
How could we best leverage “a country of geniuses in a datacenter” (1) to explore massive scientific datasets and unveil discoveries?
When it comes to astrophysics, we are producing imaging data at a scale that makes manual interpretation impossible. These datasets contain hundreds of millions of galaxy images, and upcoming telescopes will increase this to billions. Extracting scientific value from survey datasets has traditionally required human annotation, even in the age of machine learning. However, human labelling is often limited to predefined categories and requires substantial time and coordination. We need semantic search: the ability to search based on meaning.
AION-Search uses large language models (LLMs) that can process image data, such as GPT-4, to generate captions for unlabeled galaxy images and is the first system to enable meaning-based search across galaxy images with absolutely no human annotation required. It allows researchers to search by scientific intent rather than label availability, an essential tool for exploring massive datasets for rare phenomena in which the majority of observed objects may not be cataloged or classified at all.
Under the hood, AION-Search works in three steps:
1. Caption generation
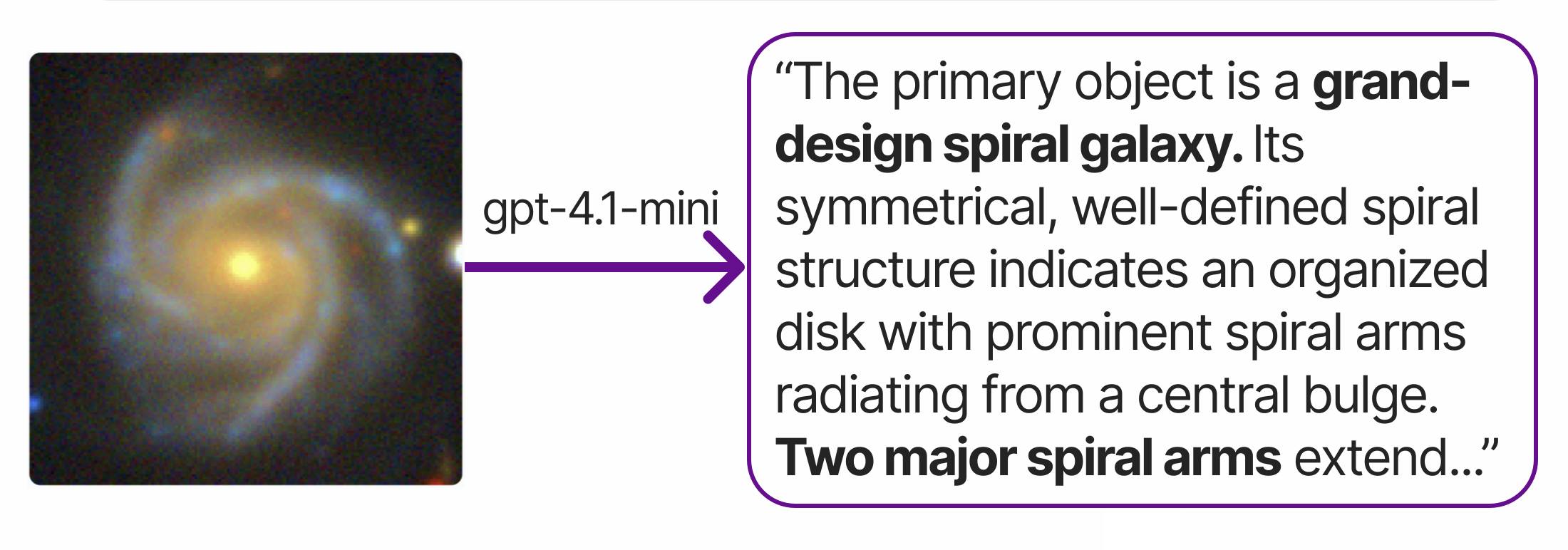
First, a galaxy image is shown to an image-capable language model (such as GPT-4.1-mini) and it is asked to describe the observable features in scientific terms. The model produces short descriptions (e.g., “face-on spiral with two arms and a central bar”), which are then converted into numerical representations that encode the meaning of the description. These captions serve as the semantic reference that later allows the system to search by concept rather than by visual similarity.
At this point, one might ask: if captions already provide a searchable semantic representation, why not simply generate captions for all galaxies?
The answer is cost.
Generating high-quality scientific descriptions for every image using vision-language models would be computationally and financially prohibitive. We need a way to obtain these semantic representations directly from images, without having to caption each one individually.
2. Contrastive alignment
To address this, we train the model so that images and their corresponding descriptions end up close to each other in the same representation space. The image embedding from AION-1 and the meaning embedding from the caption are pulled together, while mismatched image-text pairs are pushed apart. This process is referred to as contrastive learning. After alignment, the model can predict the semantic embedding directly from an image, eliminating the need to generate captions for every sample. We use AION-1 here because its representations are already physically meaningful and well-suited for capturing galaxy morphology (learn more about AION-1 here).
This is where we get the ability to search massive datasets with language queries such as “visible spiral arms”:

3. Improving discovery with re-ranking
After a semantic query is made, the system retrieves images whose embeddings are closest to the query in semantic space. For rare or subtle phenomena, only a small fraction of these candidates may be true matches. In a traditional workflow, a human expert would now manually examine the top few hundred images to determine which ones actually contain the feature of interest.
Instead, AION-Search delegates this review step to a more capable model which evaluates each candidate and assigns a relevance score based on how well it matches the query. The results are then reordered according to these scores and targeted phenomena rise to the top of the list—useful especially when searching for rare phenomena such as strong gravitational lenses.

Implications
For the first time, astronomers can free-form search datasets with millions of images just using the search engine. Through this, researchers will not only be able to find the objects they have in mind, but potentially land on new, serendipitous discoveries, or unknown unknowns! We believe AION-Search is a flexible way to explore these sorts of large, image-based datasets, and that similar technology applied to other domains of science could change how researchers interact with data.
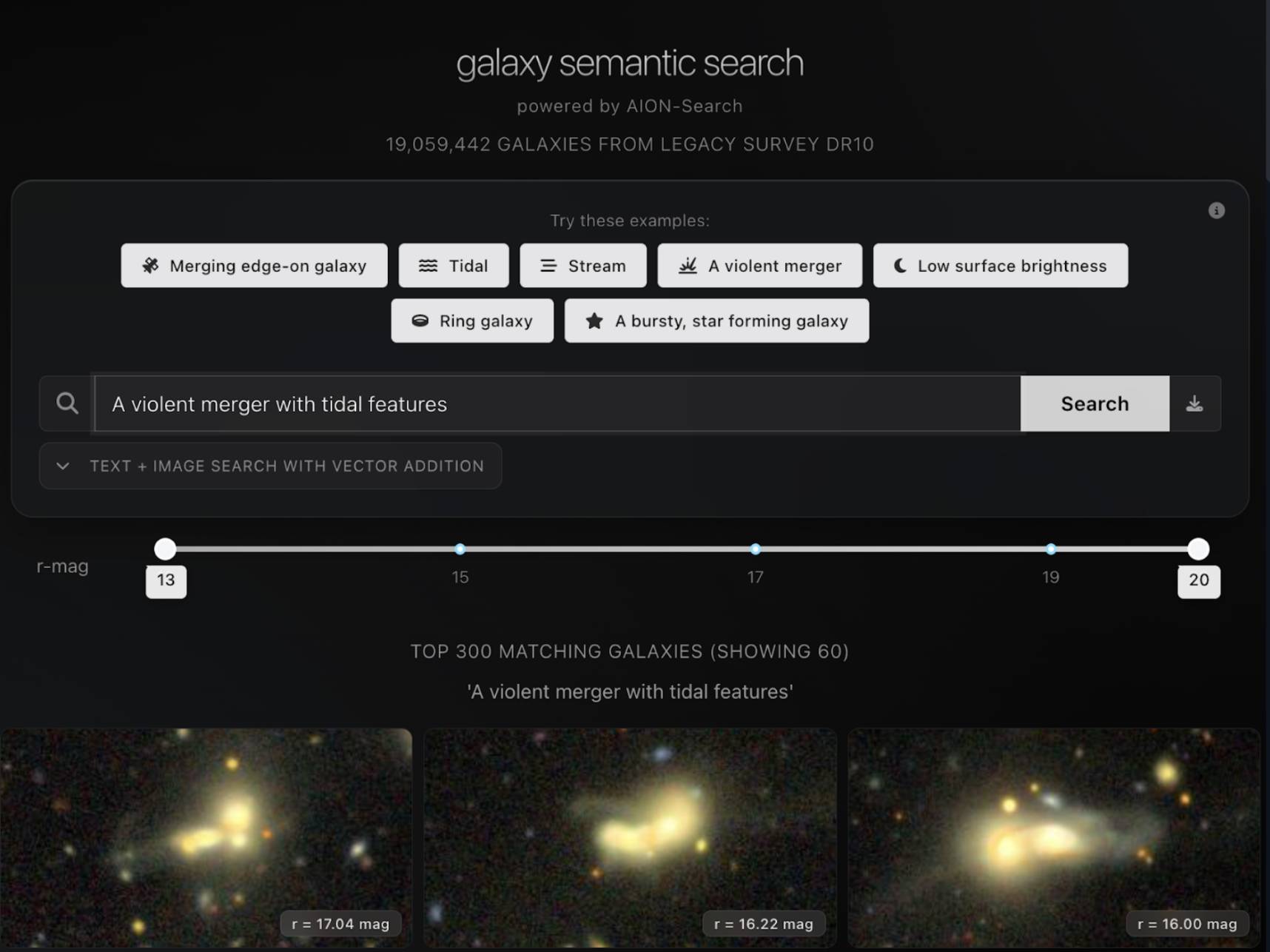
Try out AION-Search!
We have a public app to enable search over a ~20 million galaxy subset of the full dataset.
– Sophie Barstein, Nolan Koblischke
References.
(1) Dario Amodei, "Machines of Loving Grace", 2024.
Cover image credit: DESI Legacy Imaging Surveys