One of the main goals of our initiative is to create systems that connect knowledge across the conventional boundaries of science. Indeed, in a wide variety of physical domains, there exist multiple disjoint ways of measuring the same underlying systems, and so far machine learning solutions have been specialized to particular types of measurement. Therefore, developing methods that can extract information from diverse observations and represent it in a shared embedding space is an exciting avenue of exploration to unify observational modalities.
A particularly important area in science in which to deploy cross-modal connections is in large-scale, astronomical galaxy surveys. The current generation of these surveys contains between ten of millions to billions of galaxies, and different telescopes and instruments give us access to different kinds of observations. In particular in this work, we consider imaging surveys, which give us color images of galaxies, and spectroscopic surveys, which instead of images, measure optical spectra of galaxies (i.e. a quantitative measure of the light from the galaxy as a function of wavelength). Both types of observations are complementary; they give us different information about these galaxies.
However, the scale of these datasets, combined with the lack of high-quality labels and representations of these galaxies, renders the detailed analysis of these surveys challenging for researchers. Machine learning has been applied as a potential solution for a long time to discover structure in this data. Yet, so far, most machine learning work in this area has treated these different types of observations completely separately, despite all being related to the same underlying physical objects.
Our system, AstroCLIP, takes inspiration from CLIP (Contrastive Language Image Pretraining) [1]. This paper, along with subsequent works, have demonstrated that pre-training models to connect two separate types of data modalities (in that case, text and images) into a shared latent space yields high quality models which can easily be used for zero- and few- shot transfer to downstream tasks. Therefore, our goal is to extract information about the galaxies in these surveys from both image and spectra representations, embed that information into a shared embedding space,, and then align spectra-images pairs around shared semantics. Similar to the findings in text and images approaches, we show that this method allows us to create embeddings that capture high-level physical information about the galaxies that can be used for downstream tasks with very limited amounts of further data or training.
In the process, we also introduce the first transformer-based model for galaxy spectra, along with an effective pre-training strategy for this model.
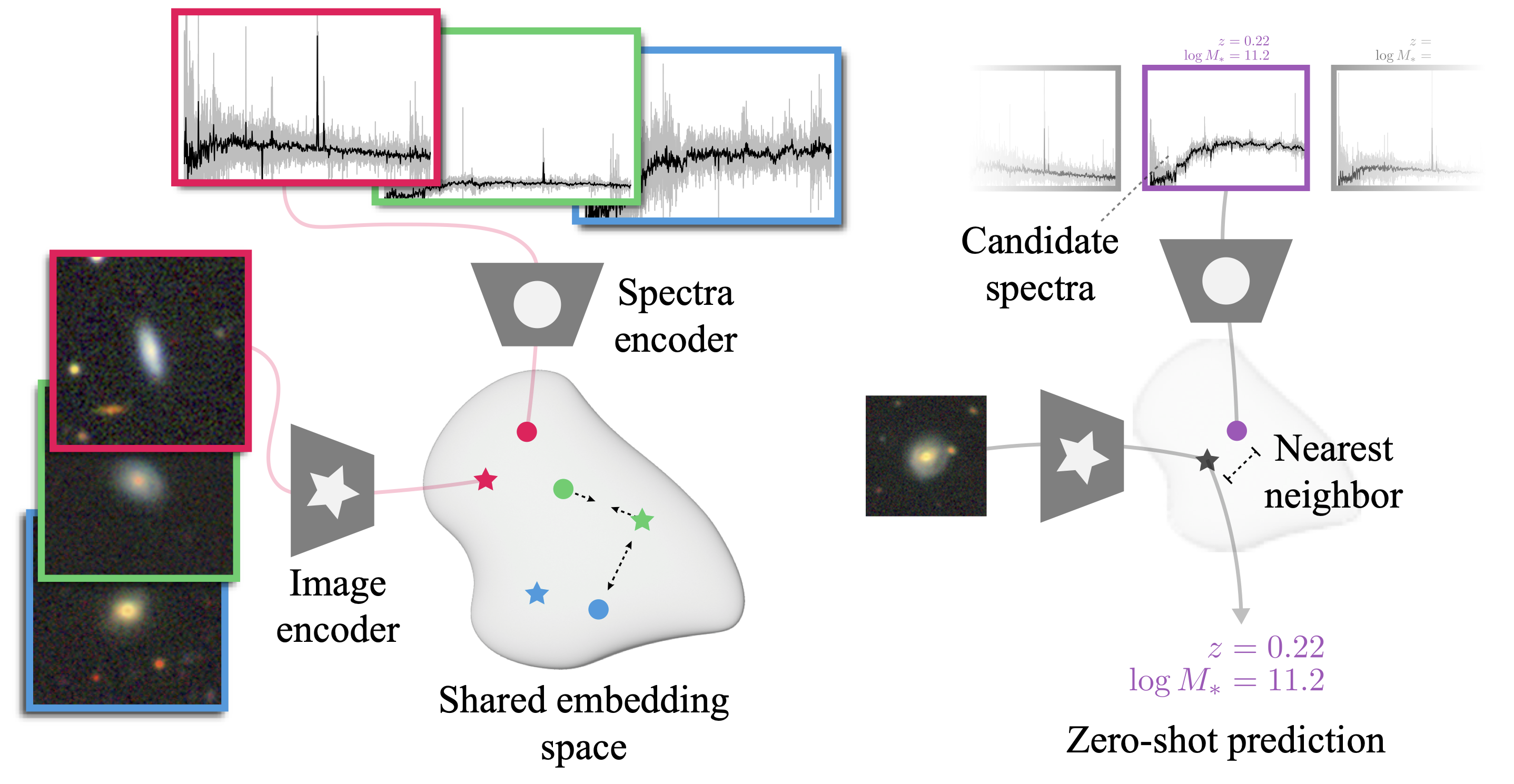
Method
At the core of our work is the idea that different observational modalities can be thought of as filtered views of the same underlying physical processes. They therefore intrinsically possess a shared physical latent space. We aim to construct embeddings of both modalities that maximize the mutual information about the underlying object, and then to use that non-zero mutual information to align representations from different modalities around shared semantics.
To that end, we employ the following pre-training strategy for AstroCLIP: Pre-train a transformer-based spectrum encoder with a similar structure to GPT-2 [2] to learn to infer masked, contiguous segments of the spectrum in a self-supervised regime. Take a convolutional image model [3] pre-trained to match galaxy images that have undergone physical augmentations and corruptions. Fine-tune both models under a contrastive objective to maximize the similarity between image-spectra pairs of the same galaxy while minimizing the similarity between pairs of different galaxies.
The figure above shows on the left how the contrastive loss naturally will tend to force the embeddings of corresponding pairs of observations of the same galaxy to be close to each other in the embedding space. This forces image and spectra embeddings to align with the underlying physical information, shared by both data modalities.Having pre-trained AstroCLIP, we demonstrate the two main capacities of this pretrained model:
Semantically Aligned Embedding Space
We show that our embedding scheme is able to align representations of galaxies both in-modality and cross-modality around meaningful shared semantics. Specifically, we query our embedding space with either the image or spectrum representation of a galaxy, and show that the retrieved galaxies by cosine similarity of their embeddings are extremely close to the original one. Below, we present all four retrieval types (spectrum-spectrum, image-image, spectrum-image, and image-spectrum, from left to right) for four randomly chosen query galaxies in our testing set (highlighted in red on the left).
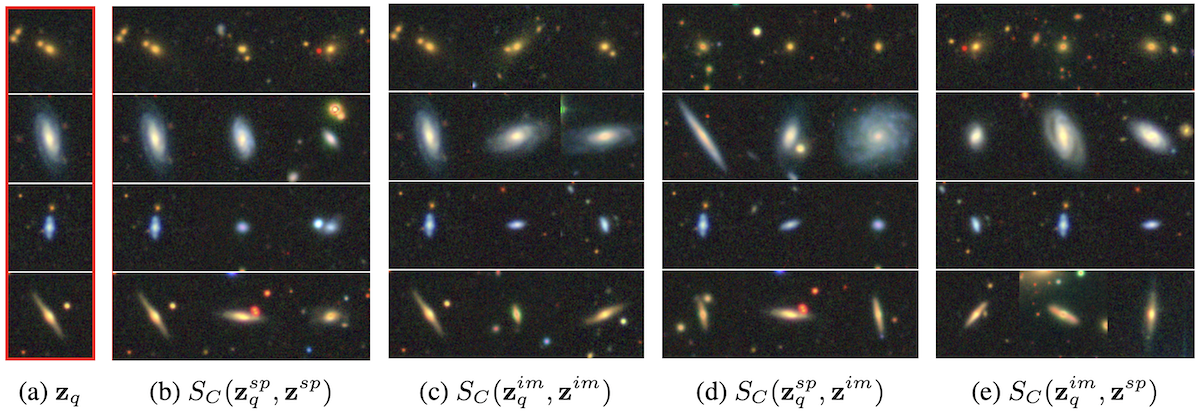
As one can see, the retrieved examples are galaxies of similar types, both for in-modality retrieval (b and c) and cross-modal retrieval (d and e).
We also present a couple of examples for the retrieved spectra, for both spectra queries (in-modality) and image queries (cross-modality) below:
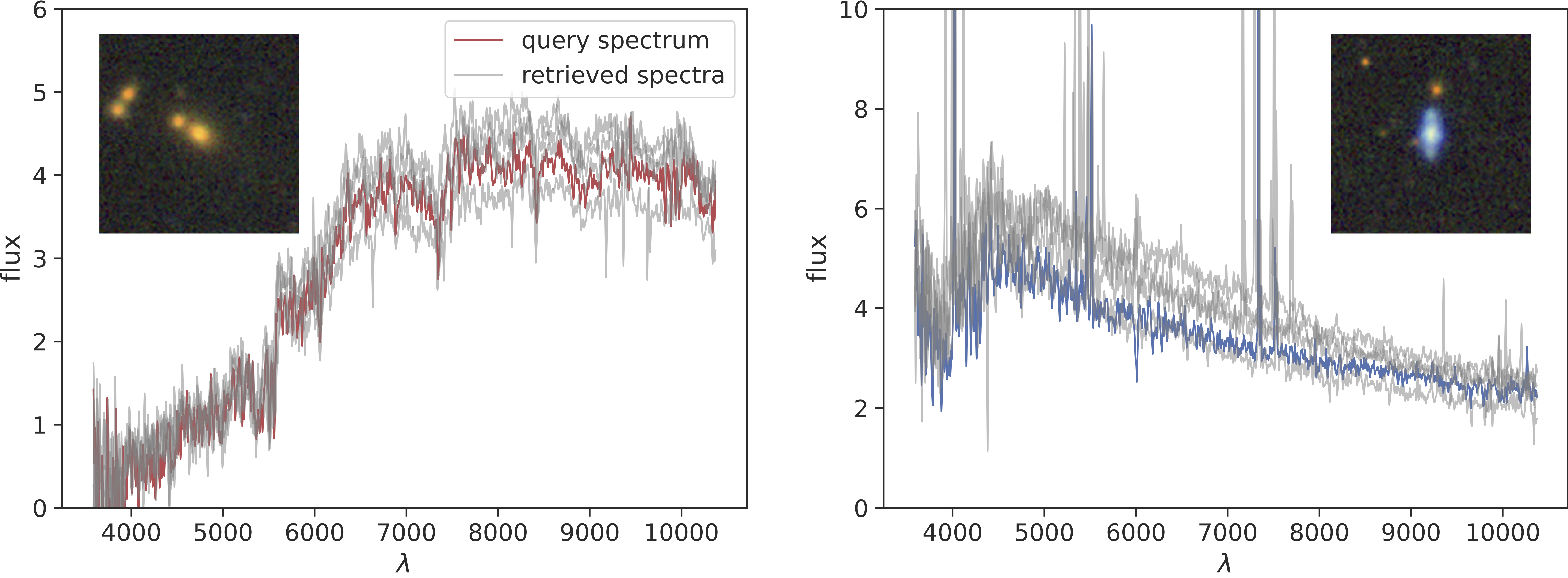
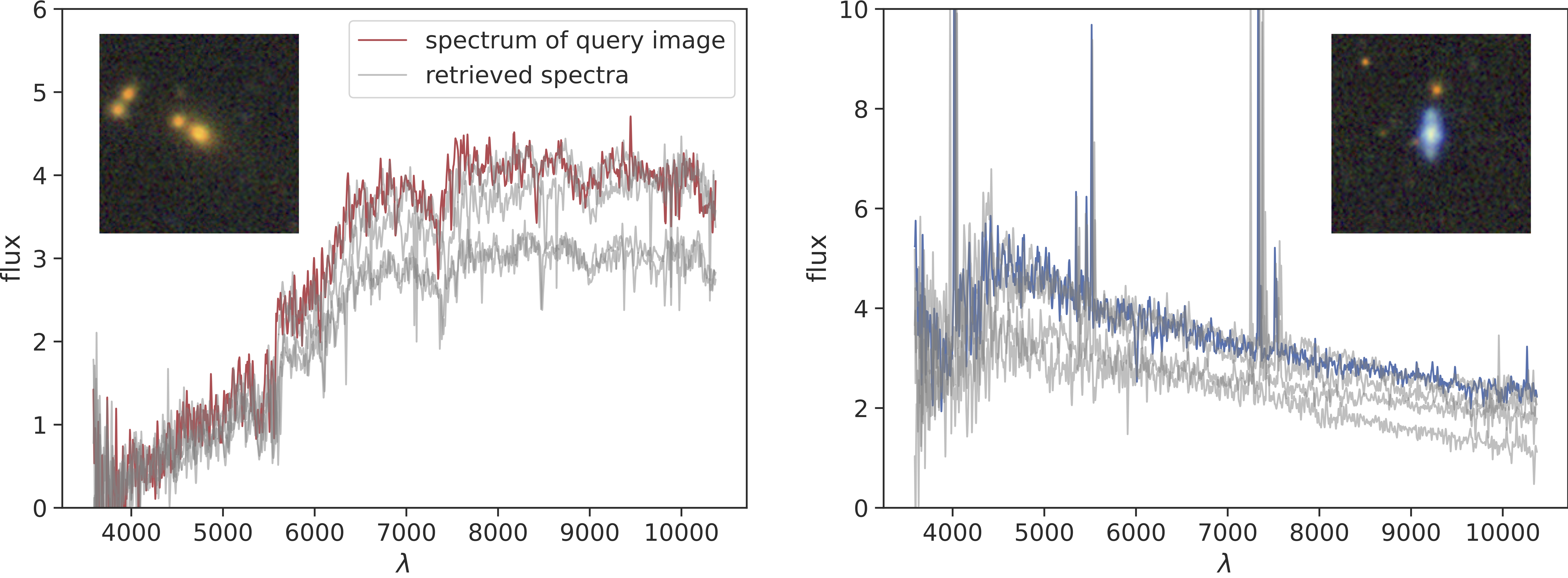
These results demonstrate a strong correlation between the semantic content of the query, such as the red quiescent galaxy or a blue star forming galaxy, and the semantic content of the retrieved images or spectra.
Powerful Feature Extraction for Downstream Tasks
In addition to constructing a semantically aligned embedding space that spans astrophysical modalities, we also demonstrate that our extracted, high-level representations of galaxies contain powerful physical information that can be zero-shot applied to downstream tasks.
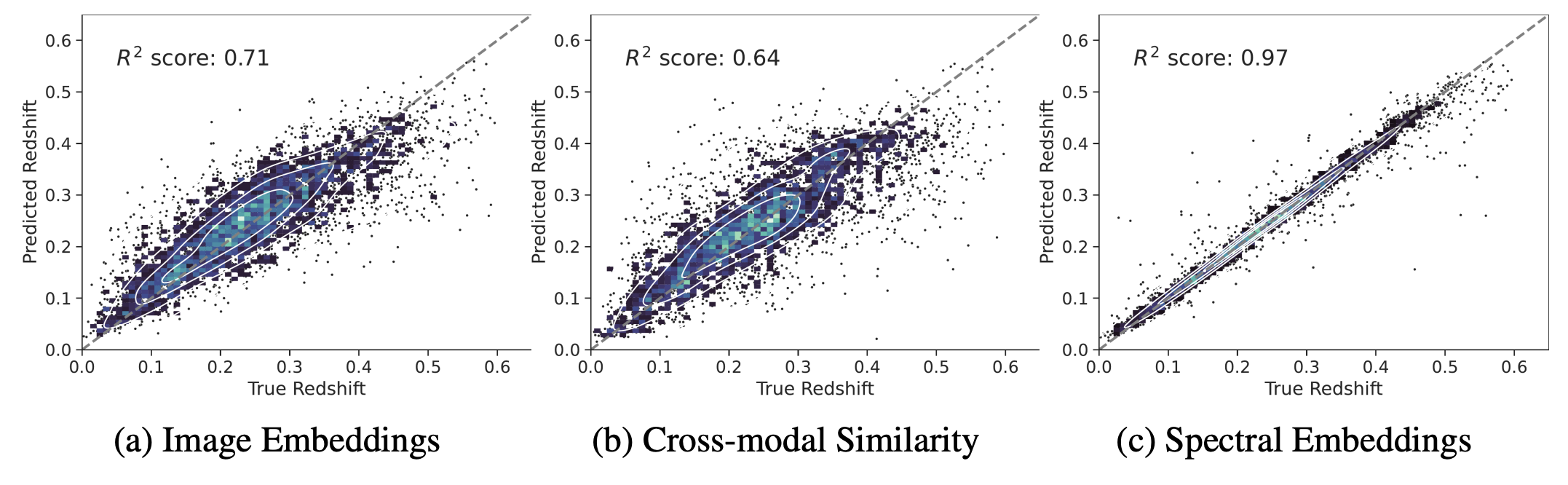
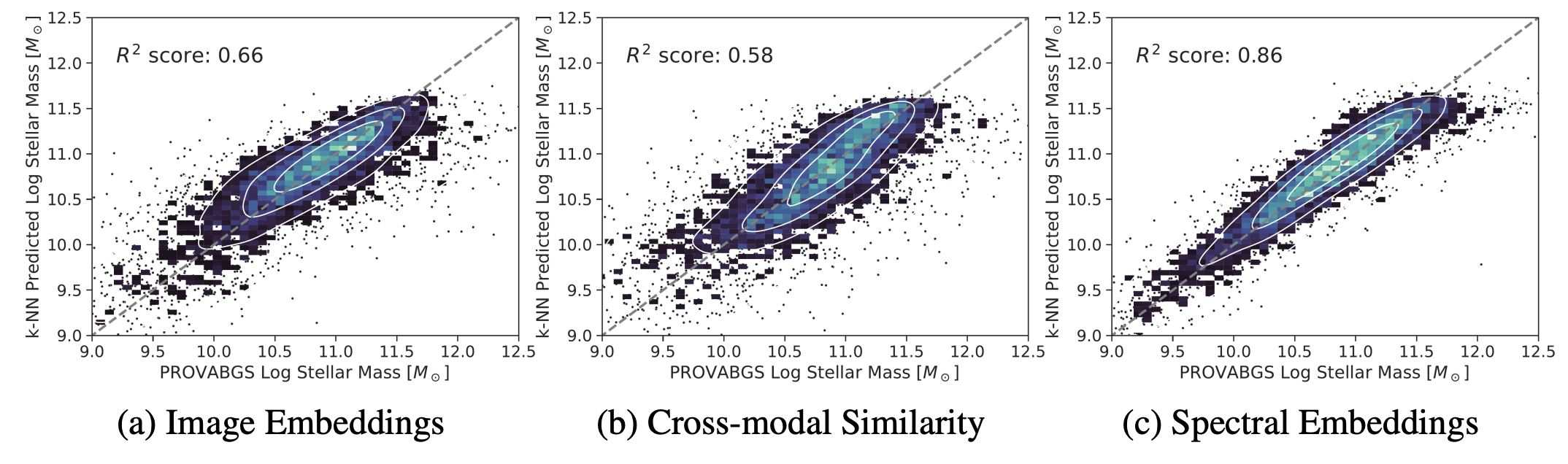
In particular, we use simple k-Nearest Neighbour (k-NN) regression of our embedded images and spectra to infer the particular redshift and the stellar mass of our galaxies. We show that neighbors in our embedded space indeed share similar physical properties, as demonstrated by the ability of our k-NN regressor to make accurate predictions. This indicates that our model is able to organize our galaxy samples according to high-level physical features.
Additionally, in-modality similarity appears to outperform cross-modality similarity as an input for the k-NN regression, indicating that, although our our contrastive training aims to connect embeddings between modalities, it has the emergent property of helping to structure the embeddings space within respective modalities. This is particularly evident for the redshift prediction (c, top panel) by similarity between spectra which is near perfect, even though redshift is not an information perfectly contained in images. This means that redshift has naturally emerged as a fundamental property which helps the spectral encoder to structure its embedding space.
Conclusions
Our results demonstrate the potential for cross-modal contrastive pre-training to achieve high quality foundation models for astronomical data, which can be used for further downstream tasks even without fine-tuning. We contend that this is a key property to allow the community to build higher-level compositional models that can rely on off-the-shelf frozen embedding models, just as frozen CLIP embeddings have enabled a wide variety of downstream applications. Moreover, we demonstrate that cross-modal connections can be effectively deployed in scientific contexts, and lay the groundwork for future even broader cross-modal scientific connections.
[1] Radford. Learning Transferable Visual Models From Natural Language Supervision https://arxiv.org/abs/2103.00020
[2] Radford. Language Models are Unsupervised Multi-Task Learners. https://insightcivic.s3.us-east-1.amazonaws.com/language-models.pdf
[3] Stein. Self-Supervised Similarity Search for Large Scientific Datasets. https://arxiv.org/pdf/2110.13151.pdf
Title image from Pawel Czerwinski.