
Astronomy has always been a data-rich science — but in recent years, the sheer volume and complexity of that data have skyrocketed. Today, many researchers turn to machine learning (ML) to handle tasks involving imaging, spectra, and time-series measurements of millions of astrophysical phenomena. However, many of the astronomical surveys in use today store data in specialized ways, making integration extremely time-consuming. Indeed, researchers might spend weeks or months just on data engineering.
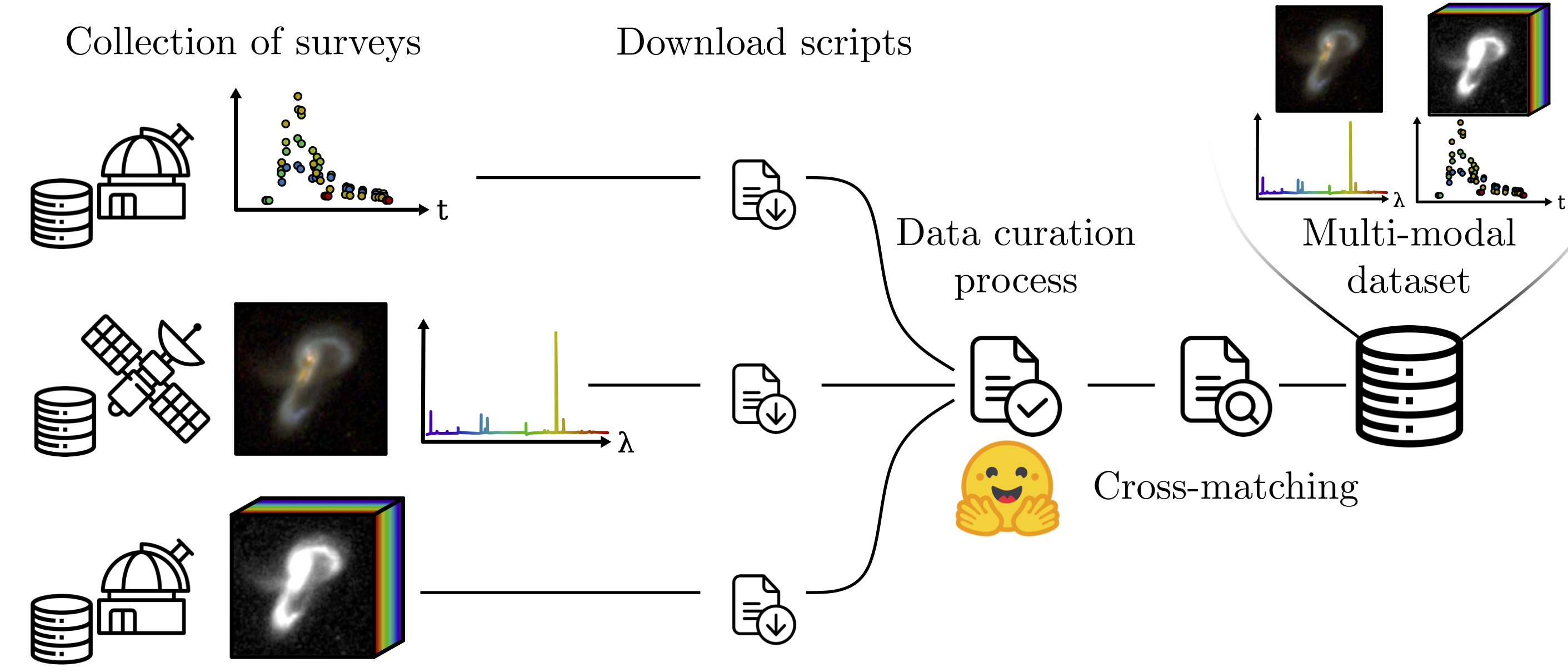
That’s why we’re excited to have partnered with the Multimodal Universe collaboration to introduce a new, large-scale curated collection of standardized data designed to accelerate ML research in astronomy. If you’ve ever dreamed of having a unified resource that seamlessly ties together images, spectra, time-series, and more, from multiple surveys, we built the Multimodal Universe with you in mind.
Why “Multimodal”?
Multimodal data refers to data that comes in multiple formats or “modalities” for a given object. For example, an image of a galaxy is a two-dimensional array of pixel intensities, while a spectrum encodes brightness at different wavelengths, and a time series captures how the brightness of a source evolves over time. Each of these modalities offers a unique window into the physics of the source under study, which is why pairing them in a single dataset can be particularly powerful.
What’s in the Multimodal Universe?
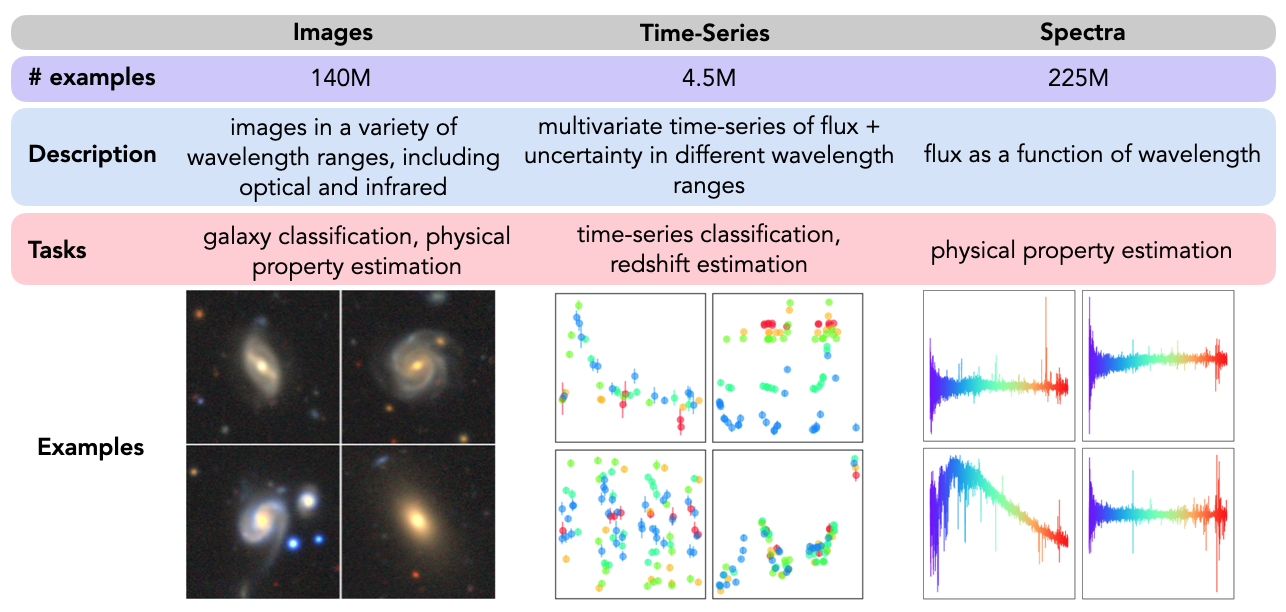
We’ve combined publicly available data from major astronomical surveys into one consistently cross-matched framework, summarized in the table below. Images, spectra, hyperspectral data cubes, time-series data… they’re all in here! Each dataset has been carefully pre-processed, documented, and aligned to play nicely with one another right out of the box.
Up-to-date instructions on how to download the data, plus details about cross-matching and referencing the original sources, can be found on the Multimodal Universe GitHub.
Key Principles and Features
By collating these diverse surveys and ensuring that each dataset aligns with the rest, the Multimodal Universe follows a few guiding principles:
-
Multimodal Alignment
We provide careful cross-matching between surveys, so you can instantly gather all available data — images, spectra, time-series, etc. — for a given source. -
Standardized Data Formats
We unify data storage and metadata standards, making it simpler to combine or swap in new surveys. -
Comprehensive Documentation
We detail relevant selection effects and biases. If your research depends on subtle coverage issues or redshift limits, we’ve got you covered. -
Public Availability of All Scripts
All the code used to download, process, and collate the data is public. This ensures transparency and makes it easy to replicate the entire pipeline or trace the lineage of each dataset from the ground up.
A Catalyst for Machine Learning in Astronomy
We’ve provided a suite of benchmarks in the paper that highlight key scenarios in which this dataset shines. For instance, we replicate the AstroCLIP project [1] by combining Legacy Survey images with DESI spectra in just a few lines of code, whereas the original paper required a large data engineering effort.
Even better, by unifying the underlying data framework, pipelines developed for one survey or modality can be directly transferred to others. This paves the way for large-scale ML models that draw from multiple instruments and data formats simultaneously.
Finally, challenges like distribution shifts, uncertainty quantification, and model calibration are crucial in scientific ML. The Multimodal Universe’s breadth and diversity of data naturally test the limits of ML model generalizability:
Where to Find It and What’s Next
We host the Multimodal Universe dataset in full at the Flatiron Institute, with the first official release corresponding to the data listed in the table. However, this is an ongoing project and will be regularly updated:
- New surveys and instruments will be incorporated as they release public data.
- Infrastructure improvements will support better data discovery and access patterns.
- Cross-matched catalogs will be refined to seamlessly link complementary observations.
We envision this living dataset as a central hub for ML-driven astronomy, drastically cutting down on the data-engineering overhead that has historically slowed progress.
Getting Started
Below is a brief overview on how to jumpstart your research with MMU:
-
Visit the Landing Page
Head to the Multimodal Universe GitHub for the latest version, plus scripts for data retrieval and usage. -
Grab Your Citations
We provide a simple script that automatically generates BibTeX citations and acknowledgements for the specific surveys you use. That’s one less thing to worry about when you publish results! -
Contribute Your Data
Check out our contribution guide if you have data (observations, simulations, or curated samples) you’d like to include.
Whether you’re building a classifier to find elusive supernovae or training a generative model to imagine galaxies we haven’t observed yet, the Multimodal Universe is here to jumpstart your ML x astronomy research. We can’t wait to see what you discover!
– Liam Parker
References
- Parker, Liam, et al. “AstroCLIP: a cross-modal foundation model for galaxies.” Monthly Notices of the Royal Astronomical Society 531.4 (2024): 4990-5011.