Transformer-based PDE surrogates have become remarkably capable, but they still inherit a basic limitation from vision models: they usually rely on a fixed patch size. In practice, that means a model is trained and deployed at one tokenization scale, with little flexibility if a user later wants higher fidelity, lower compute cost, or better long-rollout behavior.
In our new paper, we introduce Overtone, a framework that makes patch-based physics emulators much more flexible at inference time. A single trained model can run at different patch or stride settings depending on the available compute budget, so users can trade speed against accuracy without retraining. Just as importantly, we show that cyclically changing the patching pattern during autoregressive rollout has a second benefit: it reduces the structured harmonic artifacts that fixed-patch models often accumulate over long horizons.
Across challenging 2D and 3D PDE benchmarks, Overtone gives users practical control over inference-time compute and produces cleaner, more stable long rollouts.
Why fixed patching is limiting
Patch-based tokenization is one reason transformer surrogates are practical for spatiotemporal physics. By grouping pixels or grid cells into patches, the model reduces the number of tokens and therefore the cost of attention. But this convenience comes with two drawbacks.
First, fixed patching makes inference compute rigid. If a user wants a faster prediction, or wants to spend more compute for better fidelity, the usual answer is to train and maintain separate models at different patch sizes. That becomes increasingly awkward as PDE surrogates and foundation models get larger and more expensive to train.
Second, fixed patching can introduce structured long-horizon errors. In autoregressive rollouts, using the same patch grid at every step means that discretization errors reappear at the same patch-lattice frequencies again and again. Over time, those errors can reinforce each other, leading to spectral spikes and visible grid-like artifacts in the predicted fields.
Overtone addresses both problems at once: it makes tokenization controllable at inference time, and it uses that control to improve long-rollout stability.
What Overtone changes
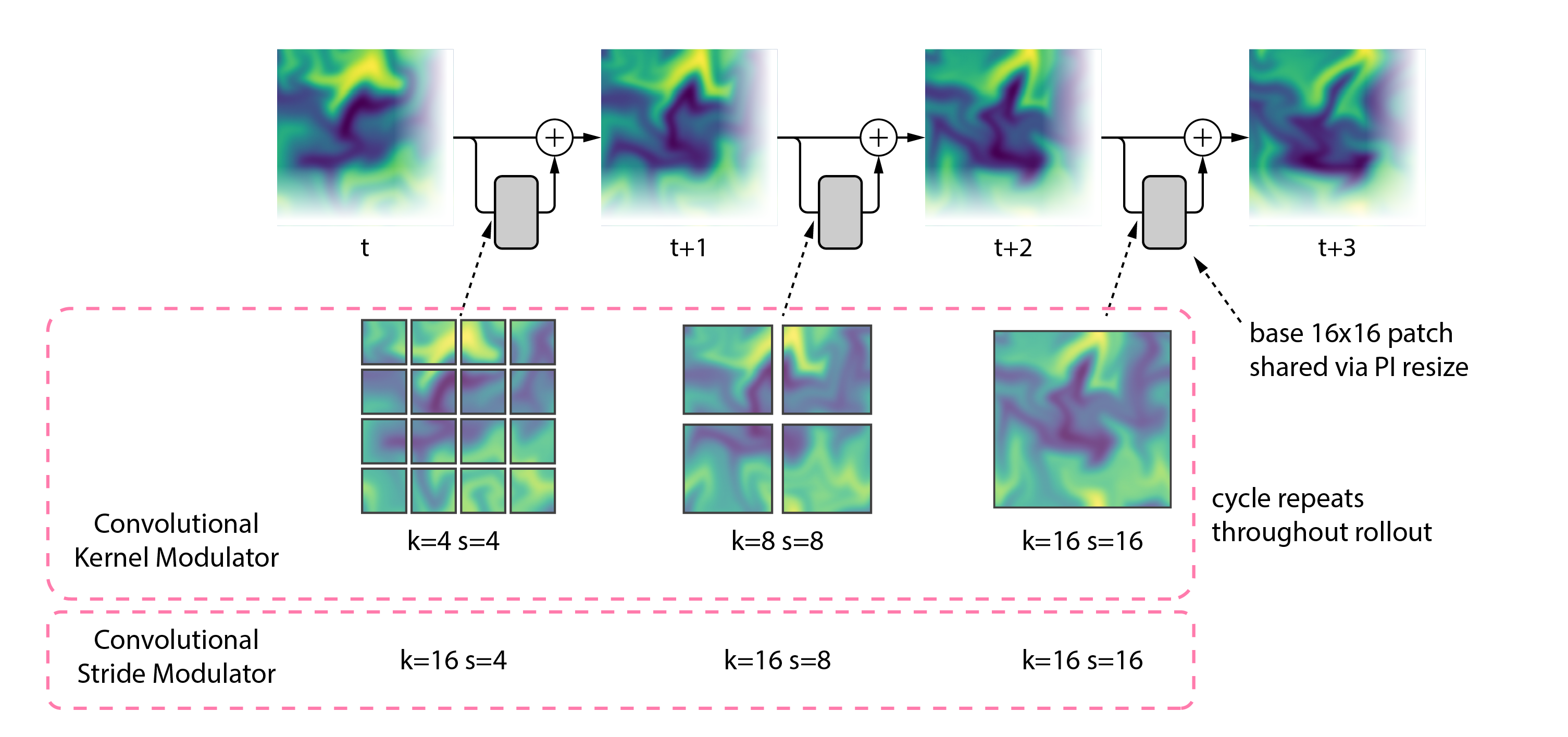
Overtone introduces two architecture-agnostic modules for patch-based PDE transformers:
- Convolutional Stride Modulation (CSM): keeps the convolutional kernel fixed, but changes the stride dynamically.
- Convolutional Kernel Modulation (CKM): resizes the convolutional kernel itself, so the effective patch size can change across forward passes.
Both methods let a single trained model operate at multiple tokenization scales at inference time. In practice, that means the same model can run with smaller patches for higher accuracy or larger patches for lower compute cost, depending on the application.
This flexibility also enables something fixed-patch surrogates cannot do: inference-time rollout schedules. Instead of using one patch size forever, Overtone can cycle through several, for example:
4 → 8 → 16 → 4 → 8 → 16
That turns tokenization into an inference-time control knob and changes how rollout errors accumulate in frequency space.
Compute flexibility: one model, multiple deployment budgets
A central motivation for Overtone is deployment. In many scientific settings, the available compute at inference time is not fixed ahead of time. Sometimes users want the best accuracy they can get. Sometimes they need a faster forecast. Sometimes they want to probe several operating points quickly, without retraining a new model each time.
This raises a practical question: how should we spend a fixed training budget? One option is to train several separate fixed-patch models, each aimed at a different compute-accuracy regime. Overtone takes a different route. We use that budget to train a single flexible model that can operate across multiple tokenization settings at inference time. In our experiments, we train three fixed-patch baselines separately at patch sizes 4, 8, and 16, while training CSM and CKM once under the same total compute budget.
The result is a single model that can be evaluated at different token counts, giving a direct compute-accuracy trade-off at inference time.
This matters because smaller patches usually improve fidelity, but they also increase attention cost. With conventional patch-based surrogates, using that trade-off means training separate models from scratch. With Overtone, the same trade-off becomes available on demand within one model.
Across 2D and 3D PDE benchmarks from The Well, we find that a single Overtone model can match or exceed multiple fixed-patch baselines across several inference-time operating points, while removing the need to train and maintain separate models for each patch size.
Cyclic patch modulation reduces harmonic artifacts
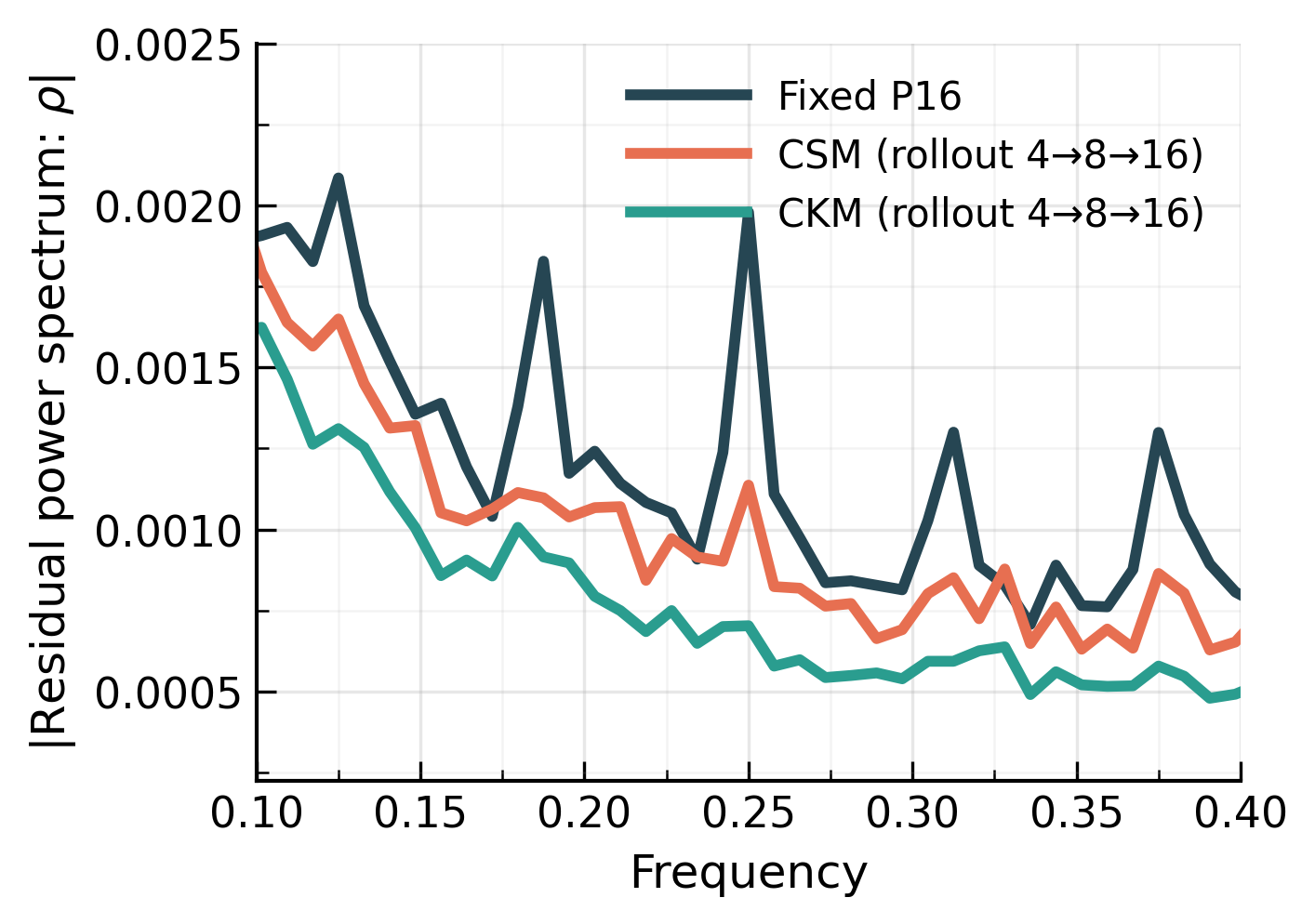
The second main result of the paper is that this approach not only improves compute flexibility, but also improves the predictions themselves.
When a model rolls out autoregressively using the same patch size at every step, the patch lattice stays fixed. That means the same boundary-related errors can be injected at the same spatial frequencies over and over. We show that this leads to harmonic artifact accumulation: residual power piles up at patch-related harmonics, and visible grid patterns appear in the predicted fields.
Cyclic schedules break that coherence. By varying the patch or stride size across rollout steps, Overtone prevents errors from repeatedly reinforcing at the same frequencies. Instead, the error gets spread more broadly, which reduces the structured buildup that causes checkerboard-like artifacts.
In practice, this gives visibly cleaner rollouts and lower long-horizon error. Across our experiments, cyclic modulation reduces 10-step rollout VRMSE by up to 30-40% relative to conventional fixed-patch baselines.
A new inference-time control knob: rollout schedules
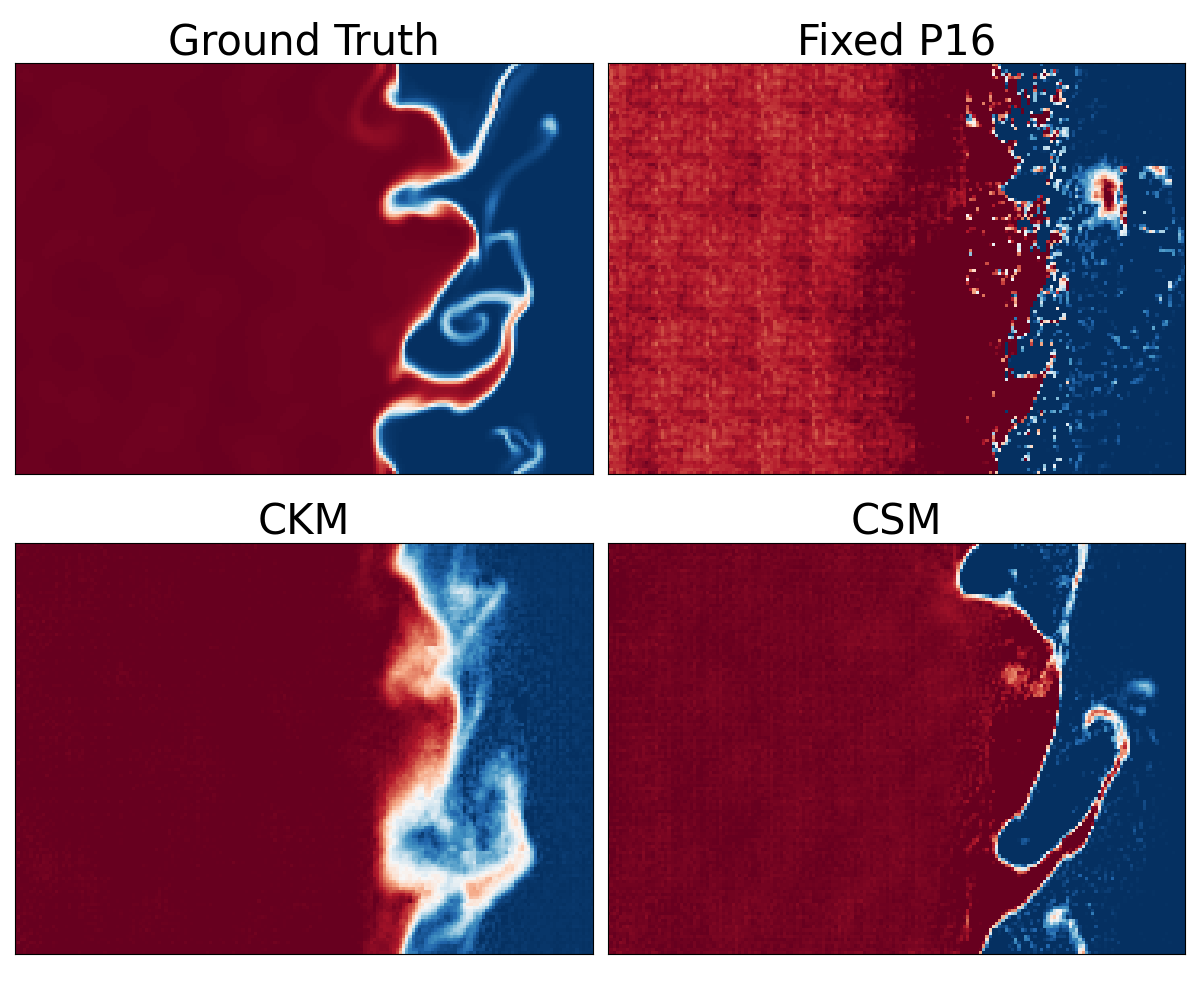
One of the more interesting consequences of Overtone is that tokenization no longer has to stay fixed during rollout. Once the model supports multiple patch or stride settings, we can control not just the scale of tokenization, but also when and how it changes.
We explored several inference-time rollout schedules, including simple periodic cycles, two-step dwell schedules, warm-up schedules, and random schedules. The schedule choice matters quite a bit. Not every way of varying tokenization works equally well. In our experiments, simple structured schedules like 4 → 8 → 16 often performed best, while random schedules could noticeably hurt rollout quality. We think the best choice will depend on other factors like the model architecture or the dataset.
Results across diverse physics systems
We evaluated Overtone on challenging 2D and 3D datasets from The Well, spanning fluid dynamics, astrophysics, and active matter. These include systems such as:
- Shear Flow
- Turbulent Radiative Layer 2D
- Rayleigh-Benard convection
- Active Matter
- Supernova Explosion
- Turbulence Gravity Cooling
Across these datasets, the same two advantages keep showing up.
First, the flexible models provide a useful compute-accuracy trade-off at inference time, allowing one model to cover multiple deployment regimes.
Second, cyclic schedules yield cleaner and more stable rollouts than fixed-patch baselines, with lower long-horizon error and much weaker patch artifacts.
We also show that the method is architecture-agnostic. Overtone works not only with vanilla and axial ViTs, but also with newer hybrid architectures such as CViT, where it again improves performance while preserving inference-time flexibility.
Looking ahead
We think this idea extends beyond the particular models in this paper. Any patch-based autoregressive model, whether in physics, video, or another spatiotemporal domain, could benefit from more flexible inference-time tokenization.
There are several directions worth exploring next. Instead of using simple cyclic schedules, one could imagine adaptive schedules that respond to the evolving state of the rollout. More broadly, these ideas should become even more useful in large pretrained multiphysics foundation models, where a single network is expected to support many downstream tasks with different fidelity and compute requirements. Recent work has already pushed in this direction at scale by incorporating CSM into the large multiphysics foundation model Walrus, where it performed well across a wide range of 2D and 3D systems.
As physics foundation models grow larger and see wider use, giving users finer control over both compute and rollout behavior will matter more. Overtone is one step in that direction.
Open source resources
Code and materials:
- Paper: Overtone: Cyclic Patch Modulation for Clean, Efficient, and Flexible Physics Emulators
- Code: GitHub
– Payel Mukhopadhyay, Michael McCabe, Ruben Ohana, Miles Cranmer
Acknowledgements
Polymathic AI gratefully acknowledges funding from the Simons Foundation and Schmidt Sciences, LLC. Payel Mukhopadhyay thanks the Infosys-Cambridge AI Centre for support. We also thank the Scientific Computing Core at the Flatiron Institute for computational support, and the broader Polymathic AI team for valuable discussions and feedback.