
Simulation is one of the cornerstone tools of modern science and engineering. Using simulation-based techniques, scientists can ask how their ideas, actions, and designs will interact with the physical world. Yet this power is not without costs. Cutting edge simulations can often take months of supercomputer time. Surrogate models and machine learning are promising alternatives for accelerating these workflows, but the data hunger of machine learning has limited their impact to data-rich domains. Over the last few years, researchers have sought to side-step this data dependence through the use of foundation models— large models pretrained on large amounts of data which can accelerate the learning process by transferring knowledge from similar inputs, but this is not without its own challenges.
Why is it so Hard to Build a Foundation Model for Physical Simulation?
Physical simulation is an enormously broad field. It can be difficult to even define what we mean by “physical simulation” since there are many varieties and scales that are regularly simulated. Here, we’re mostly speaking of “continuum-level” simulation where we’re simulating macroscopic objects as though they were coherent objects rather than astronomically large collections of molecules crashing into each other. But even at this particular level, there is still an enormous amount of diversity that must be accounted for:
- First, small changes in equations lead to big changes in physics. For example, we could use the Euler equations to model shocks and rarefaction waves in gas dynamics, but by introducing one additional term, viscosity, we get the Navier-Stokes equations which describe categorically different turbulent behavior. Now if we couple these equations with Maxwell’s equations of electromagnetism, we get the magnetohydrodynamics (MHD) equations which now describe plasmas in fusion reactors and in stars. Going down a different path, if we were to adjust the structure of that viscosity, then we might instead be modeling viscoelastic materials which straddle the line between solids and fluids. These changes look inconsequential when written as equations, but even these minor tweaks lead to wildly different physical behavior.
- Second, the structure of physical data has no single canonical template. Different physical systems are described by different collections of physical fields— velocity, density, pressure, temperature, magnetic fields, stress tensors, and more. On top of that, these fields are defined over different domains with varying aspect ratios, resolutions, and dimensionalities.
- Third, training across mixed-resolution and mixed-dimensional datasets introduces major computational imbalances. A single 3D snapshot of a system will often contain orders of magnitude more grid points than a 2D one. Without careful design, training becomes both unstable and inefficient.
- Fourth, and perhaps most importantly, the dynamics of many physical systems amplify small errors. A model that is slightly wrong at the next time step may be dramatically wrong ten steps later. Many machine learning-based approaches can be even more sensitive to these small perturbations than the real system, leading to major divergence between predictions over time.
Overcoming these challenges requires rethinking training strategies and developing new architectural tools.
Introducing Walrus
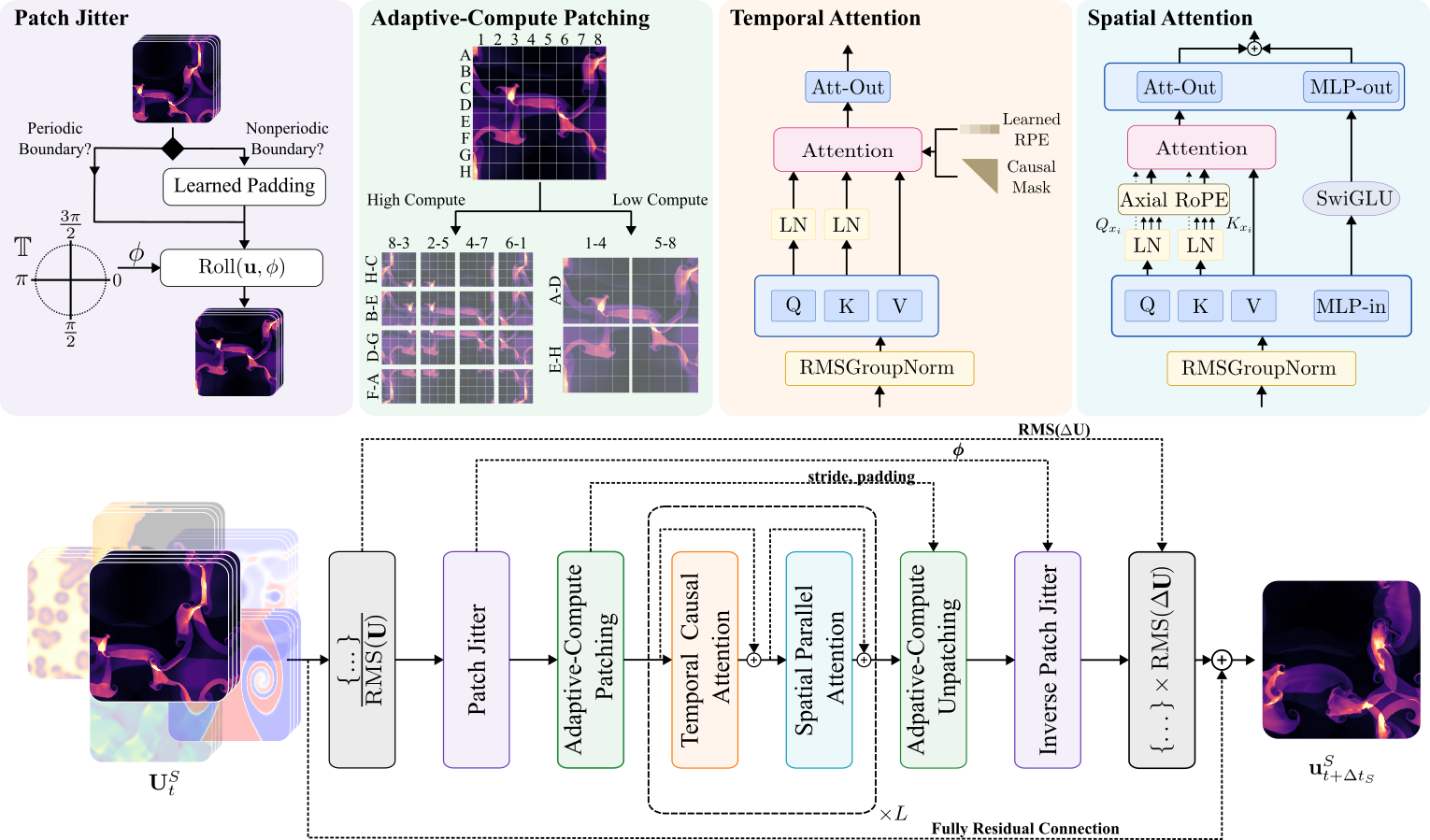
Walrus is a transformer-based model designed specifically to learn across diverse physical systems. It contains 1.3 billion parameters and is trained on a dataset of unprecedented scale and variety: 19 scenarios, encompassing 63 physical fields, drawn from areas including acoustics, classical fluids, non-Newtonian flows, plasma physics, active matter, and several high-resolution astrophysical regimes. Walrus is one of the largest, most broadly pretrained models yet for physical emulation.
The Anatomy of a Walrus
Walrus learns by watching large amounts of simulation data— movies of physical systems evolving over time. Walrus takes a short trajectory of system snapshots and predicts the next state in the system. Rather than being explicitly provided information about the equations or system coefficients, Walrus must infer this information in-context from the provided history. This allows Walrus to be used on experimental data or settings where there may not be a clean equation that models the system.
To make this possible over so many types of data, we had to build in a few ideas that help the model learn efficiently and stay accurate over long sequences:
Stabilizing the model
Many physical systems are sensitive: a tiny source of error early can be magnified by the dynamics and completely change what happens later. Machine learning models can amplify this error due to architectural choices. For example, the “patching” or “tokenization” procedure used for compression in higher dimensional transformer models can break translation equivariance, the property of physical dynamics that says that outside of boundary effects physics should not depend on the location inside a domain. Walrus avoids this by randomizing the compression process. Before downsampling, Walrus randomly “jitters” the data, so that it reads the data slightly differently each step. These tiny shifts prevent the model from locking onto grid patterns or numerical artifacts. The result is that Walrus stays stable for far longer than earlier models.
This isn’t just a heuristic. We can root this method in solid analysis of the operations used in these models, but that’s beyond the scope of this blog post, so read the paper if you want to know more.
Adaptive Compute Patching
Not all systems require the same amount of compute to emulate. Walrus is built with this in mind and uses recently developed compute-adaptive patching techniques to apply different levels of compression to different inputs. Walrus can, for instance, apply less compression to already coarse-grained data while applying more to higher resolution data to scale each problem to the available compute to maximize accuracy.
This helps us avoid some of the limitations of fixed resolution models, especially for 3D data where the trade-off between accuracy and accuracy is especially impactful.
Dimensional Augmentation
 Another key idea is treating 2D and 3D data in a unified way through shared augmentation. The presence or absence of certain fields can allow models to easily learn to predict entirely different dynamics for 2D and 3D systems, but this defeats the purpose of joint pretraining. In training Walrus, we avoid this by an aggressive augmentation strategy in which all 2D data is embedded in a 3D space, sort of like placing a sheet of paper inside a thin box, and then randomly transformed with tensor law aware transformations in time and space so that the 2D data corresponds to a random 2D plane in the 3D space.
These design choices, that are described in further detail in the paper, let Walrus do something that hasn’t been possible before: learn from extremely different kinds of physical systems— waves, fluids, plasmas, turbulence, and make predictions that stay coherent over time. The result is a model that understands enough underlying structure to perform well across many domains.
Another key idea is treating 2D and 3D data in a unified way through shared augmentation. The presence or absence of certain fields can allow models to easily learn to predict entirely different dynamics for 2D and 3D systems, but this defeats the purpose of joint pretraining. In training Walrus, we avoid this by an aggressive augmentation strategy in which all 2D data is embedded in a 3D space, sort of like placing a sheet of paper inside a thin box, and then randomly transformed with tensor law aware transformations in time and space so that the 2D data corresponds to a random 2D plane in the 3D space.
These design choices, that are described in further detail in the paper, let Walrus do something that hasn’t been possible before: learn from extremely different kinds of physical systems— waves, fluids, plasmas, turbulence, and make predictions that stay coherent over time. The result is a model that understands enough underlying structure to perform well across many domains.
Walrus in Action
Starting from a Walrus checkpoint can speed up learning for the emulation of 2D and 3D physics across an unprecedented number of equations, boundary conditions, physical parameterizations, resolutions, and aspect ratios, offering higher accuracy on downstream tasks than prior foundation models.
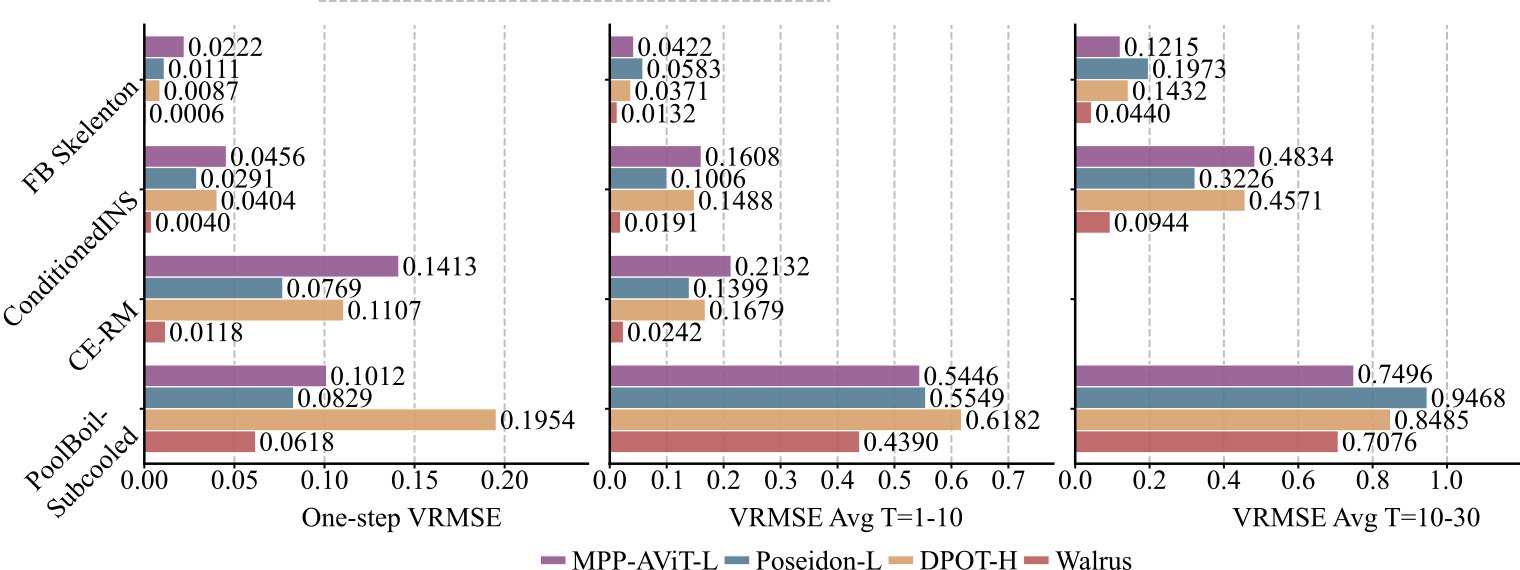
Check out the paper for more experiments, baselines, and ideas, or check out more rollout videos here.
Into the Future
The path to fully validated, production-ready machine-learned simulators will require further research, careful testing, and deeper integration with traditional methods. But Walrus shows that the foundational ideas work. It suggests a future where simulation is faster, more flexible, and more universally accessible, accelerating research across disciplines that depend on understanding the physical world.
Open Source Resources
Walrus is entirely open - model and training code. You can get started here:
- API & code: Walrus Code
- Model weights: Hugging Face
- Tutorial: Walrus Tutorial
- Paper: Walrus: A Cross-domain Foundation Model for Continuum Dynamics
– Sophie Barstein, Michael McCabe
Acknowledgements This project wouldn’t be possible without the generous support of the Simons Foundation and Schmidt Sciences, LLC. We’re grateful to have received compute support from Scientific Computing Core, a division of the Flatiron Institute, a division of the Simons Foundation and from the National AI Research Resource Pilot, including support from NVIDIA and NVIDIA’s DGX Cloud product which includes the NVIDIA AI Enterprise Software Platform.
Walrus title splash licensed from Getty Images via Unsplash+.