
Foundation models are increasingly being applied to the physical sciences, but whether they can be usefully deployed on real laboratory experiments remains an open question. We test this on Rayleigh-Taylor instability (RTI), one of the most enduring challenges in fluid dynamics. RTI drives some of the most consequential mixing processes in the Universe, from inertial confinement fusion to supernova explosions to ocean mixing. Standard ML models struggle with it, and despite more than a century of theoretical, numerical and experimental work, it carries a stubborn, unresolved discrepancy between simulation and experiment: the late-time mixing growth rate coefficient α measured in most laboratory experiments sits near 0.06-0.07, roughly three times the value from idealized direct numerical simulations which give an α between 0.02-0.03. The origin of this gap is still debated. That makes RTI a stringent test for a question that matters well beyond RTI itself: can foundation models finetuned on idealized simulations generalise to sparse, complex, and noisy laboratory data they were never trained on? The sim-experiment gap in α is a sharp quantitative test of whether that generalisation has succeeded.
We finetune Walrus, a foundation model pretrained on a broad corpus of continuum dynamics simulations, on just one to three direct numerical simulation (DNS) realizations of RTI, with no physics-informed loss. The finetuned model recovers canonical RTI diagnostics over full autoregressive rollouts. Applied zero-shot to initial conditions from real sliding-barrier laboratory experiments, with no experimental training data at any stage, its predicted late-time growth rate coefficient rises into the experimentally observed band. The result provides independent, data-driven evidence on a decades-long unresolved debate in the RTI community.
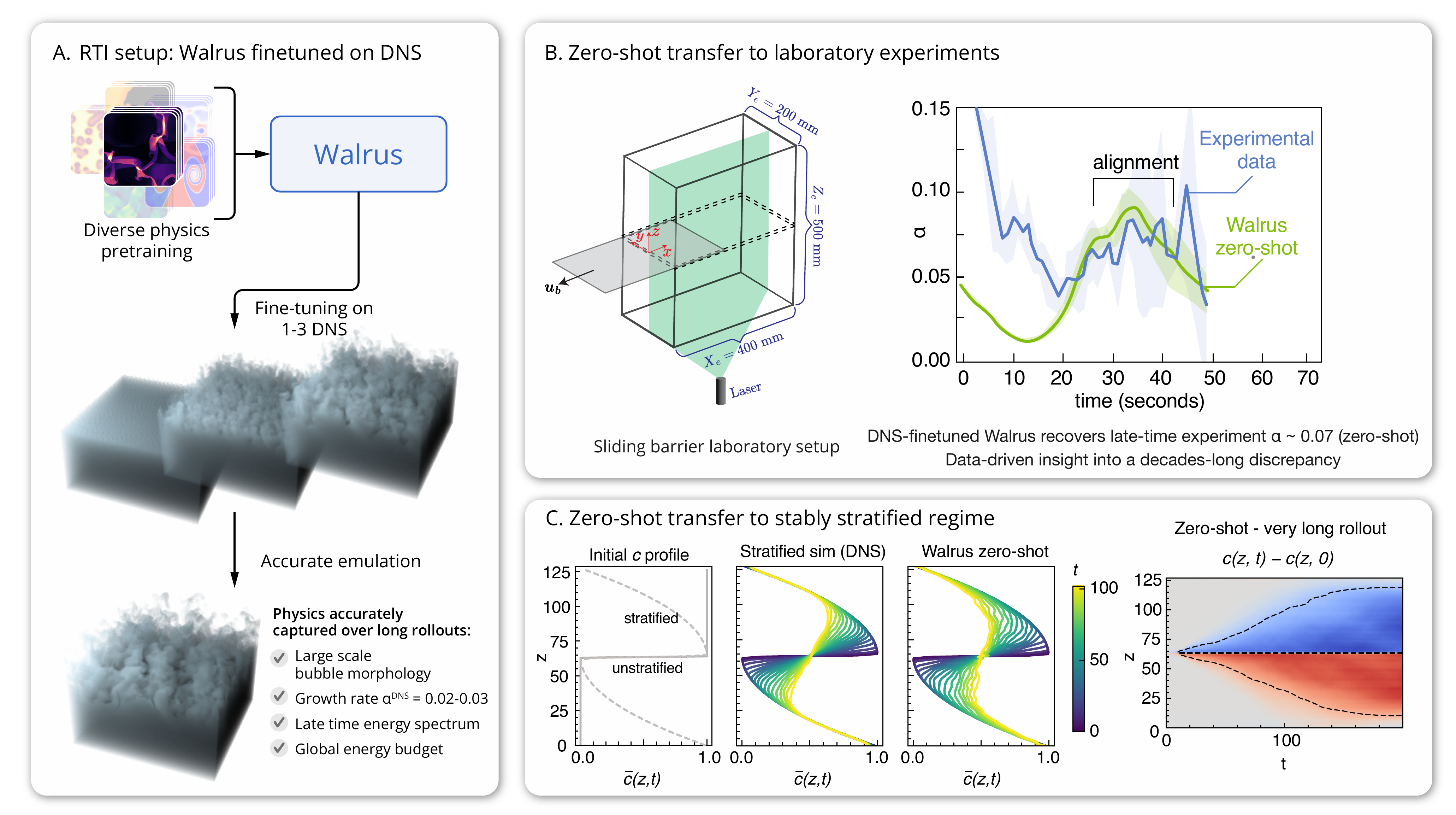
(A) Walrus finetuned on a small number of 3D RTI DNS realizations, evaluated on independent held-out simulations. (B) Zero-shot transfer to sliding-barrier experiments: Walrus enters the experimentally observed late-time growth band without any experimental training data. (C) Zero-shot transfer to stratified RTI: finetuned only on unstratified DNS, Walrus responds correctly to stable background stratification.
Why RTI is the right test case
Place a heavy fluid above a light one in a gravitational field, and the interface erupts into complexity. Fingers grow, spikes plunge, bubbles rise, and small perturbations at the density interface grow into chaotic, multiscale mixing. Standard machine learning models struggle to model RTI, and this system has a deep simulation-to-laboratory gap. In the late-time, approximately self-similar regime, the bulk mixing width follows h(t) ∼ α At g t², where At is the Atwood number, g is the acceleration, and α is the dimensionless growth rate coefficient that measures how fast the mixing layer grows. This late-time regime is the comparison that matters: idealized DNS usually settles near α ≈ 0.02-0.03, while most laboratory experiments reach α ≈ 0.06-0.07. Because the model is finetuned only on idealized DNS, it has only seen the low-α regime during training. Entering the higher experimental α band from experimental input frames at zero-shot is therefore a nontrivial test of whether the sim-to-real transfer has succeeded. If the same DNS-specialized model gives DNS-like growth from DNS frames but enters the experimental growth band from experimental frames at zero shot, then the input initial frames alone have moved it across the sim-to-real divide. This is one of the central transfer tests of our study.
Emulation: learning RTI physics from very little data
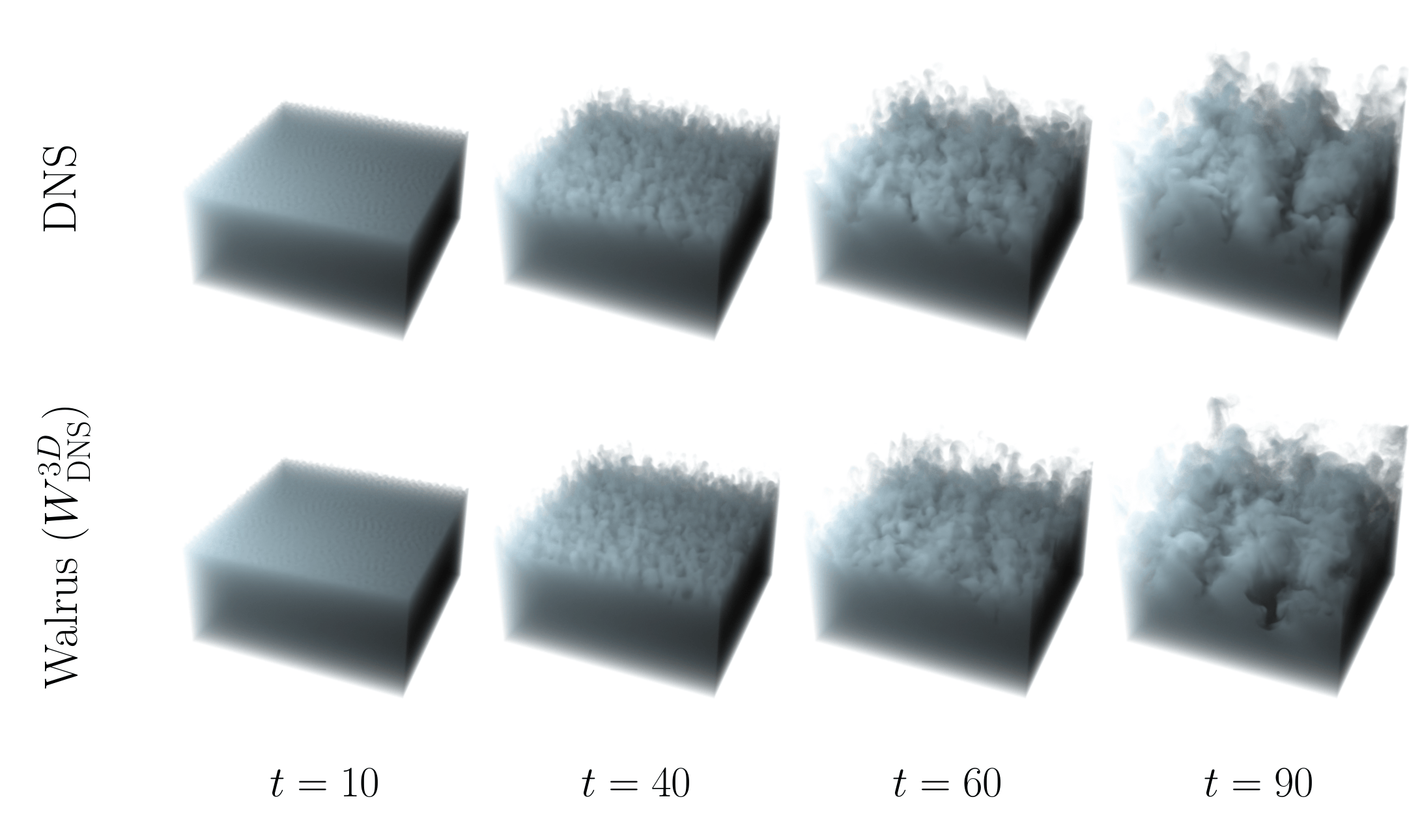
Four representative times comparing DNS (top) and Walrus (bottom) on a held-out test realization. The model tracks mixed-layer growth and preserves dominant plume structures through the nonlinear and turbulent stages.
Walrus is pretrained on a broad corpus of continuum dynamics simulations with RTI explicitly excluded, so RTI physics must be learned entirely through finetuning. We finetune on between one and three 3D DNS realizations, with no physics-informed loss. Whatever physical structure appears in the rollouts emerges from the data alone.
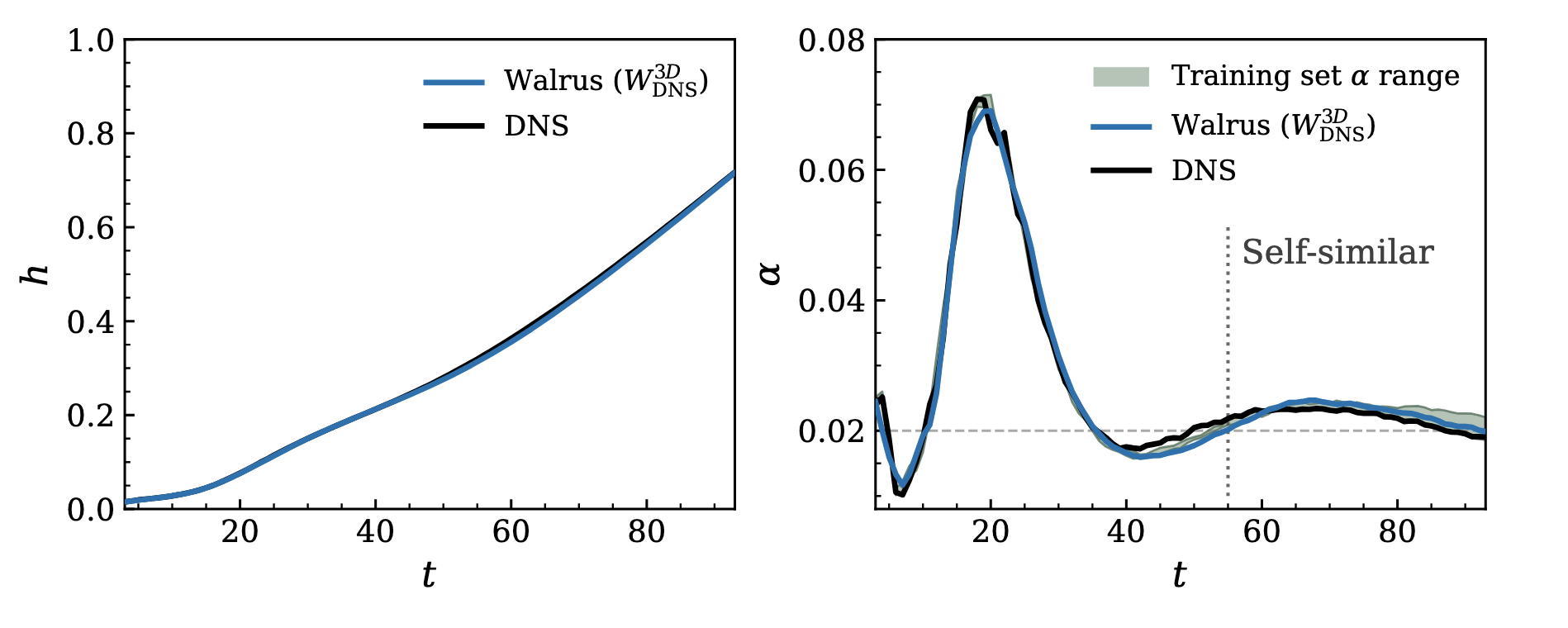
Mixing-layer height h(t) (left) and growth rate coefficient α(t) (right) on a held-out test realization. Walrus tracks the DNS closely through the full rollout, settling near α ≈ 0.02 in the self-similar regime.
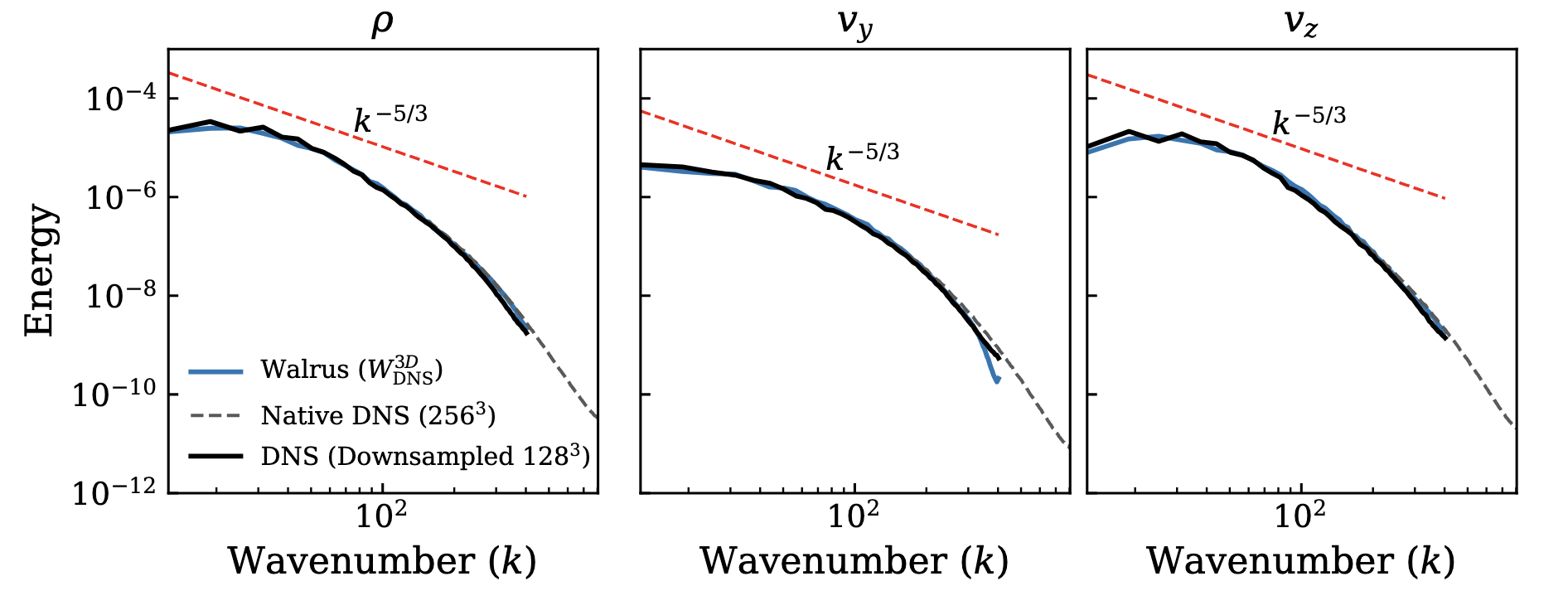
Kinetic energy spectra in the self-similar regime. Walrus matches the DNS shape and amplitude across the inertial range.
On held-out test realizations, the finetuned model recovers the canonical diagnostics simultaneously. Bubble morphology and mixed-layer growth track the DNS through the onset of turbulence. The kinetic energy spectrum matches across the inertial range. The global energy budget is reproduced over the full rollout. Conventional surrogate models typically diverge within a handful of autoregressive steps, so sustaining all three over long rollouts is a stringent test of whether the model has encoded physical structure rather than memorized specific trajectories.
Finetuning on a single DNS realization already gets close; adding a second or third tightens agreement only incrementally. The broad fluid prior means only a few examples are needed to specialize.
Sim-to-real: zero-shot transfer to the laboratory
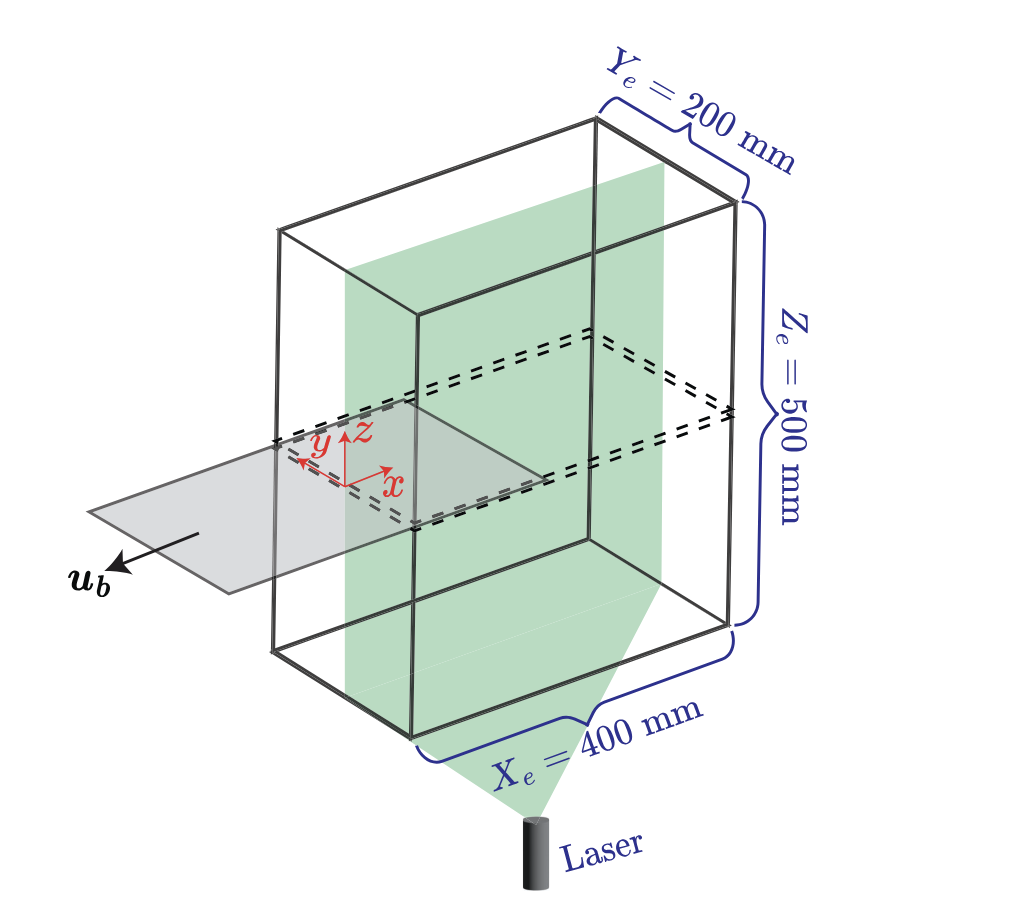
The sliding-barrier apparatus at the GK Batchelor Laboratory, Cambridge. Two fluid layers of differing density are separated by a polycarbonate barrier. At release, the interface is seeded with large-scale perturbation structure driven by barrier motion, structural vibration, and molecular diffusion.
The sim-experiment gap in α has a leading candidate explanation: initial conditions. DNS uses idealized short-wavelength perturbations at the interface. Laboratory flows carry large-scale structure set by the barrier release, driven by apparatus motion, vibration, and molecular diffusion, which is notoriously difficult to parametrize numerically. The two initial interfaces look nothing alike.
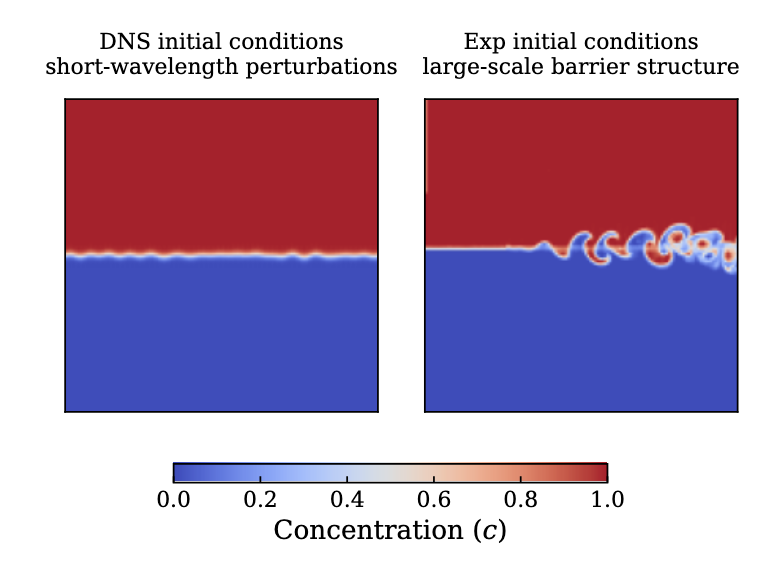
Initial concentration fields for a DNS realization (left) and a sliding-barrier experimental sample (right). The DNS interface carries short-wavelength perturbations; the experimental interface carries large-scale structure set by the barrier release. This difference is the leading candidate explanation for the factor-of-three gap in α.
We finetune Walrus on 2D slices from a single DNS realization, then apply it directly to initial conditions from six sliding-barrier laboratory experimental samples with no experimental training data at any stage. This is a highly data-limited zero-shot transfer setup.
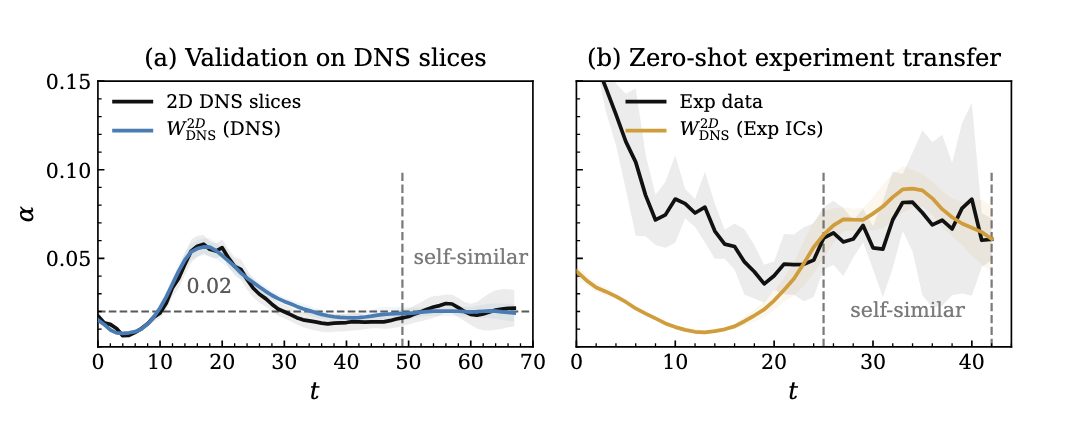
Zero-shot transfer from idealized DNS to laboratory RTI. Left: the DNS-specialized Walrus model tracks held-out 2D DNS slices and settles into the low-α DNS regime near α ≈ 0.02. Right: the same model, with the same weights, is initialized from sliding-barrier experimental frames instead. Without any experimental training data, its rollout enters the late-time experimentally observed growth band, showing that the input experimental initial conditions are sufficient to move the model across the simulation-to-laboratory gap in the late-time regime.
The DNS-specialized model, given experimental initial frames, rises into the experimentally observed self-similar band at late times. We do not expect it to reproduce the early sliding-barrier transient, which is absent from the idealized DNS used for finetuning. The meaningful comparison is the late-time regime where α is defined: the same model given DNS frames settles near α ≈ 0.02, while the model given experimental frames enters the higher experimental growth band. The only difference between the two rollouts is the input.
What this reveals about the learned representation matters more than the number itself. Self-similar RTI growth is governed by h(t) ∼ α At g t², and α depends on how the flow was seeded. The model was trained exclusively on DNS with short-wavelength initial conditions and low α. Given experimental frames carrying large-scale initial structure, it produces a higher late-time α, in the physically correct direction. The model has encoded the dependence of self-similar growth on initial condition structure, general enough to carry from the DNS-like regime to the laboratory.
That this happens from experimental initial frames alone supports the view that initial conditions drive a substantial part of the sim-experiment discrepancy in α. It is independent, data-driven evidence on a debate that has resisted resolution through simulation alone.
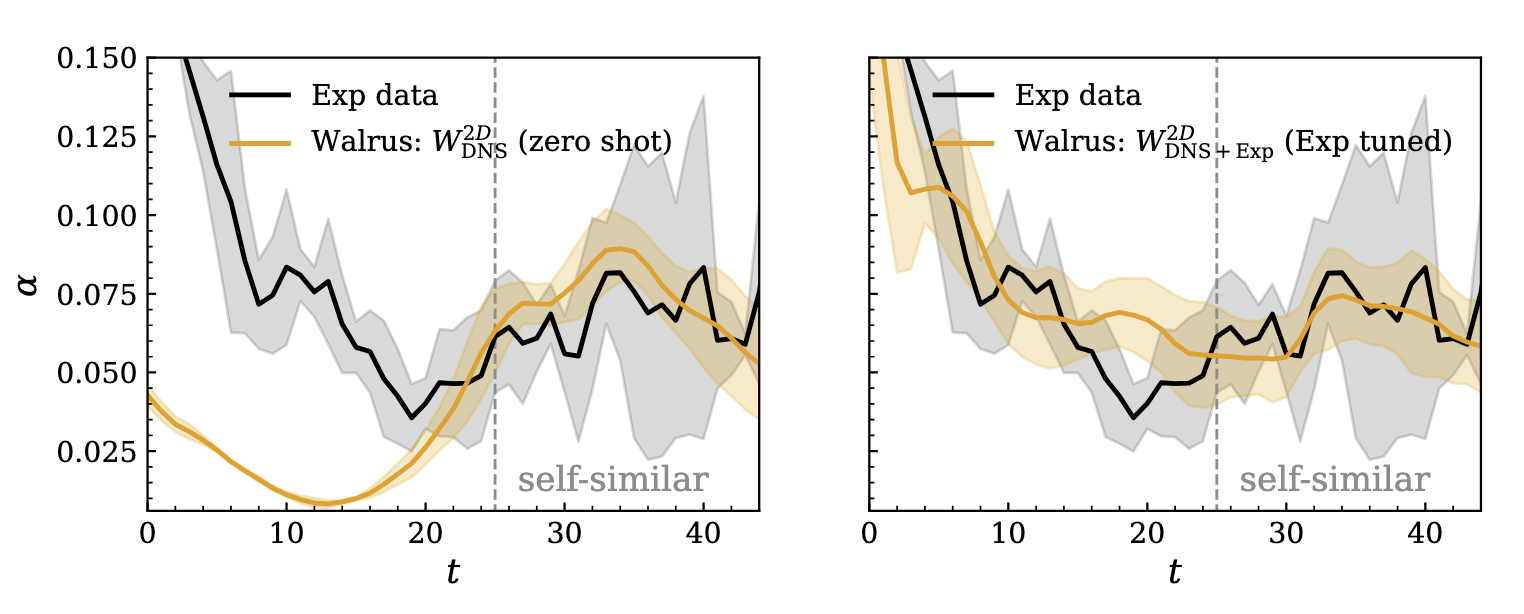
Growth rate coefficient α(t) on held-out laboratory experiments. Left: zero-shot, no experimental training data. Right: after light finetuning on two experimental samples. In both cases Walrus enters the experimentally observed late-time growth band.
The shift is robust across different amounts of input context. With just two experimental samples, a lightweight finetuning stage further improves agreement through the early transient, while the late-time α already reached zero-shot is preserved.
Zero-shot transfer to a new physical regime: stable stratification
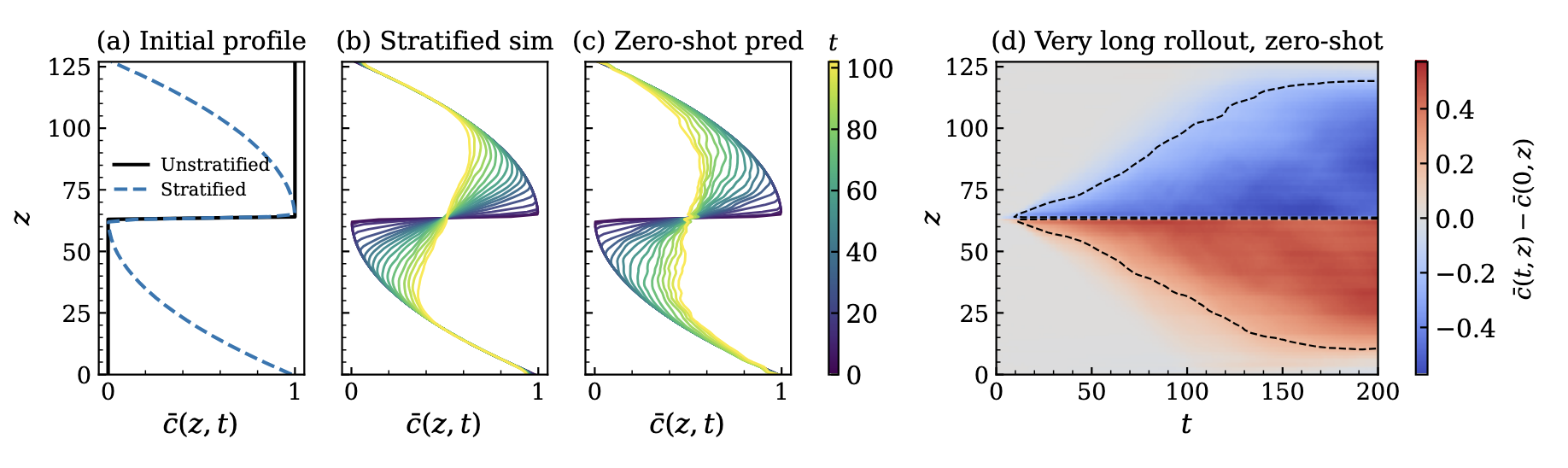
(a) Initial mean concentration profiles for the unstratified and stratified cases. (b) Mean concentration profiles from the stratified DNS reference. (c) Corresponding zero-shot Walrus rollout after finetuning only on unstratified RTI. (d) Very long zero-shot rollout out to t = 200. Stable stratification confines mixing near the midplane, and Walrus captures that response without ever seeing stratified flow during training.
The laboratory result asks whether the model can cross the sim-to-real divide. The stratified case asks something different. It asks whether the model has learned only the unstratified RTI dynamics it saw during finetuning, or whether it has learned something more general about buoyancy-driven mixing.
To test that, we change the physics while staying within the RTI family. We apply the DNS-finetuned model to stably stratified RTI, where a stable background density gradient acts as a restoring force and suppresses vertical spreading of the mixing layer. This regime was completely absent from finetuning.
That change is enough to separate the two possibilities. In the unstratified case, the mixing layer keeps spreading. In the stratified case, the partially mixed region remains confined near the midplane. A model that had only learned to continue unstratified RTI rollouts would keep opening up the layer. Walrus does not. In zero shot, it moves into the correct qualitative regime: the mean concentration profiles stay confined, in clear agreement with the stratified DNS reference.
Panel (d) pushes the same test much further. The model never saw stratified flow during training, and it never saw times this late during finetuning, yet the rollout continues into the expected decelerating, confined regime rather than drifting back toward unstratified growth.
The mismatch is in degree, not in kind. At late times Walrus spreads the layer somewhat more than the DNS reference, but it still responds to stratification in the right physical direction. For a model finetuned only on unstratified RTI, that is a strong sign that the learned representation is carrying something more general than one familiar rollout pattern. It has to encode something about how buoyancy governs mixing, and how that mixing changes when the buoyancy balance itself is altered.
What this means
RTI is a worst case. It is chaotic and multiscale, standard ML architectures fail on it, and it carries a well-quantified simulation-experiment discrepancy that has persisted for decades. A foundation model finetuned on a handful of idealized simulations transfers zero-shot to real laboratory data, sheds independent light on that debate, and responds correctly to a physical regime it was never shown.
Prior attempts to close the sim-experiment gap for RTI each required a bespoke numerical setup tailored to the specific experimental apparatus. Here, only a few experimental samples and a lightweight finetuning stage suffice.
The question of how the model achieves this transfer remains open. Until we understand that, its inferences remain, in a useful sense, a fiction. Traditional simulations and the Navier-Stokes equations are themselves fictions: approximations of true physics, just as experimental measurements are only approximate representations of the underlying flow. The question is whether foundation models offer new, useful fictions despite relying on imperfect training data. Our results suggest they do.
Open source resources
Materials:
- Paper: Emergent Transfer of a Physics Foundation Model: From Simulation to Laboratory Turbulence
- Code: GitHub
- Data: Huggingface
- Model Checkpoint: Huggingface
– Payel Mukhopadhyay, Stefan Nixon
Acknowledgements
We would like to acknowledge the support of Schmidt Sciences and the Simons Foundation. This work was supported in part by the AI2050 program at Schmidt Sciences (Grant G-25-70028). Dr. Mukhopadhyay thanks the Infosys-Cambridge AI centre for support. Additionally, computations were run at facilities supported by the Scientific Computing Core at the Flatiron Institute. The Flatiron Institute is a division of the Simons Foundation. The authors thank Lucy Reading-Ikkanda for assistance with figures. Miles Cranmer is grateful for support from the Schmidt Sciences AI2050 Early Career Fellowship and the Isaac Newton Trust. S.S. Nixon and R. Watteaux thank the CEA’s Centre de Calcul Recherche et Technologie for facilitating DNS computations. S. S. Nixon gratefully acknowledges CEA for funding his PhD research and thanks the technical staff at the G. K. Batchelor Laboratory (DAMTP, University of Cambridge) for their invaluable assistance in completing the experiments.