
A few months ago, we introduced AstroCLIP, a strategy for training cross-modal self-supervised models on scientific data. AstroCLIP addresses a primary objective of the Polymathic initiative: to develop unified systems that connect diverse scientific measurements. It tackles this objective in an astrophysics context, where the ability to handle diverse measurements is critical given the billions of varied astronomical observations available. To that end, AstroCLIP embeds complementary measurements of galaxies in a single, unified, physically meaningful embedding space, which can then be used for a variety of downstream tasks. For a full overview of the AstroCLIP method, see our previous blog post.
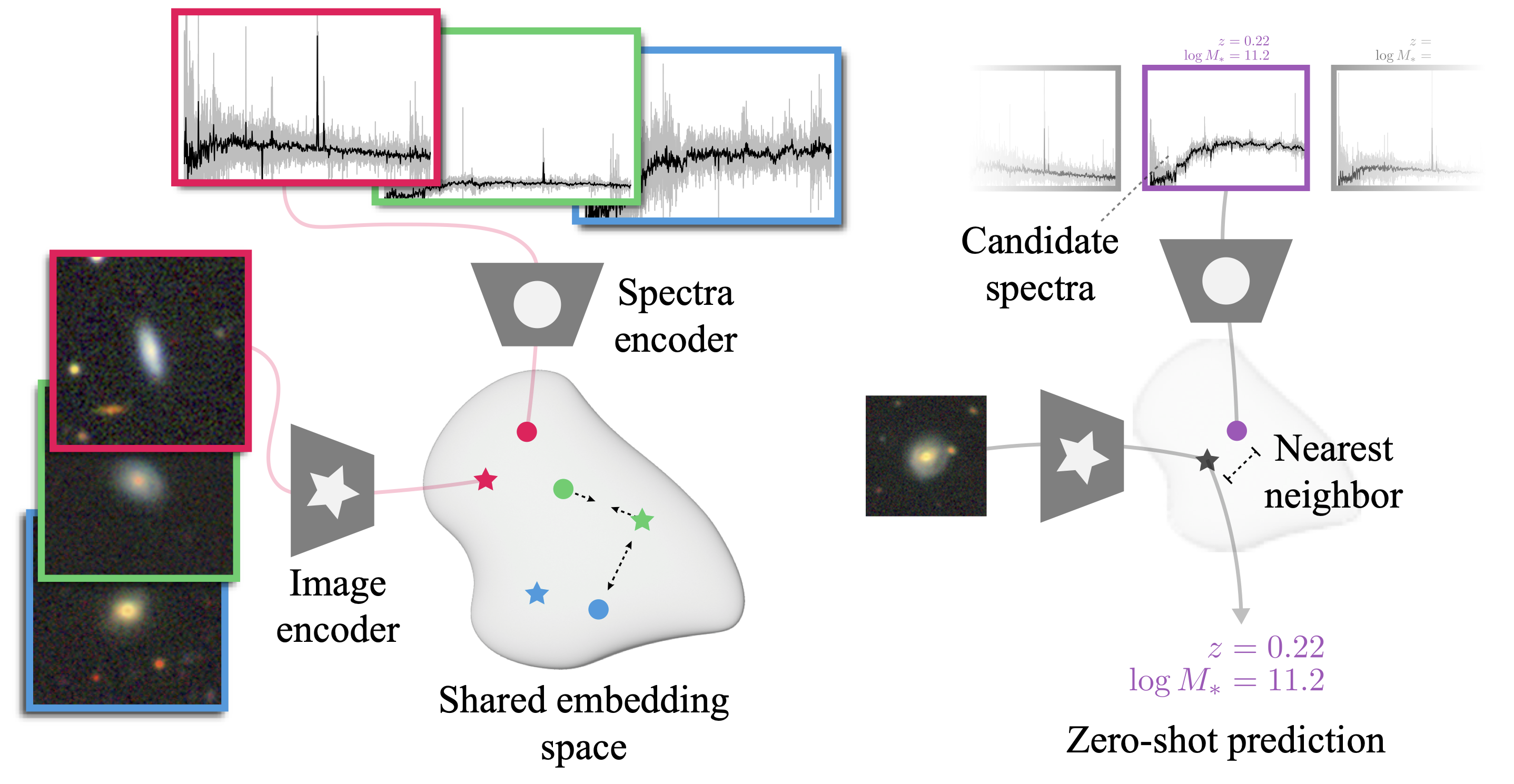
Now, we are excited to announce the release of a new and improved AstroCLIP model. This updated version outperforms the original version on all previously tested downstream tasks and introduces the capacity to tackle a host of new problems. Now, on many of these downstream tasks, AstroCLIP matches or beats the performance of dedicated, supervised deep learning models, including on tasks like redshift estimation and physical property regression, despite the fact that it has never been specifically trained or fine-tuned for any of these tasks.
Overall, AstroCLIP represents the first cross-modal foundation model for galaxies, as well as the first use of self-supervised transformers for galaxy images and spectra in astronomy. We release the full model weights, training codes, evaluation suite, and datasets here.
Web Interface
We provide below an interactive interface to explore the embeddings produced by out model.
Model Improvements
We introduce a wide variety of model improvements, the most significant of which is the use of a Vision Transformer (ViT) for image encoding. This vision transformer is trained at scale (~300M parameters) using the DINOv2 framework [1], a recent strategy for training large, self-supervised vision models. Overall, we find the galaxy image ViT pretrained with DINOv2 outperforms the previous AstroCLIP image encoder, both on its own and when integrated into the AstroCLIP framework.
Semantically Aligned Embedding Space
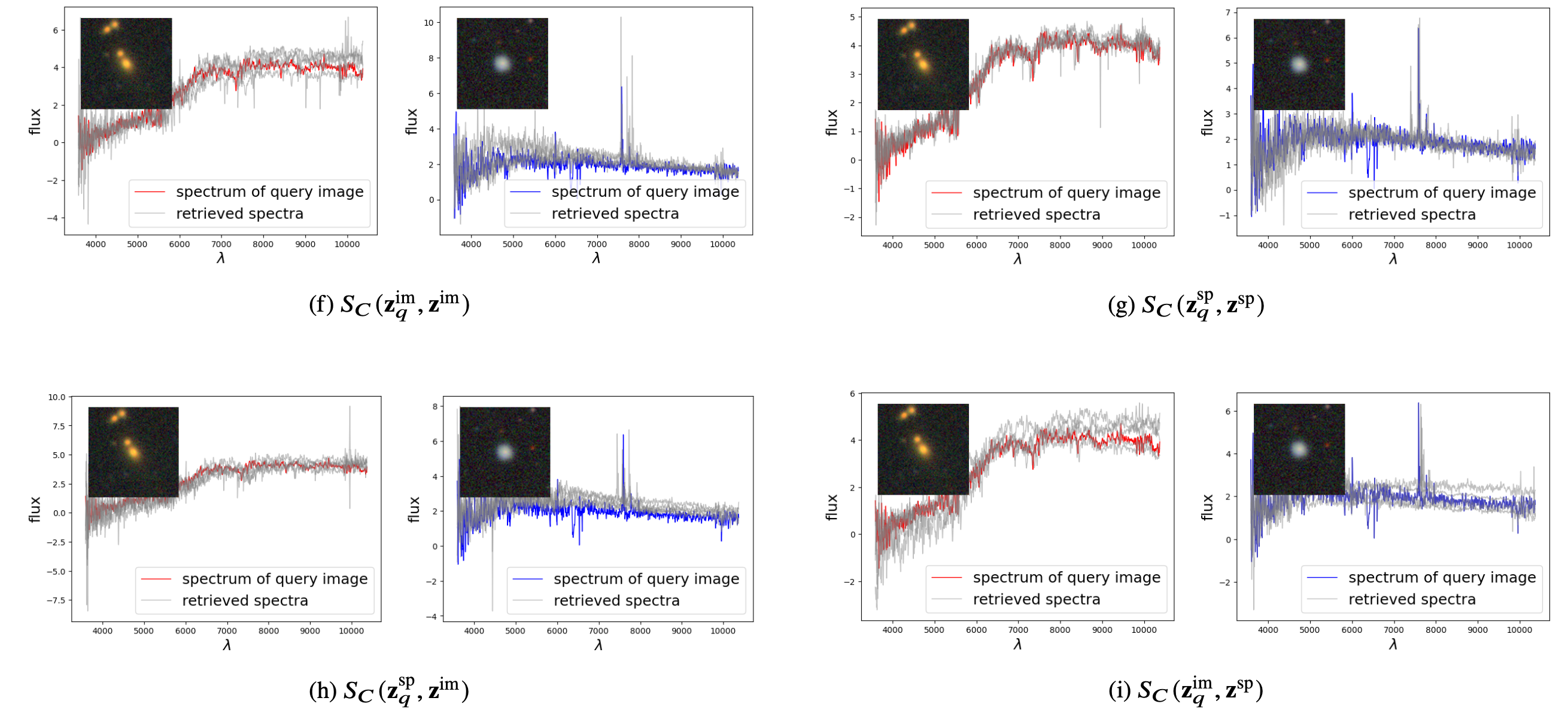
Our embedding scheme successfully aligns galaxy representations within and across modalities based on shared semantics. The retrieved galaxies via cosine similarity closely match the original AstroCLIP performance, with more well-aligned retrievals in the updated version. Below, we present all four retrieval types (spectrum-spectrum, image-image, spectrum-image, and image-spectrum, from left to right) for four randomly selected query galaxies in our testing set, highlighted in red on the left.

We also present examples of the retrieved spectra for all four retrieval types below.
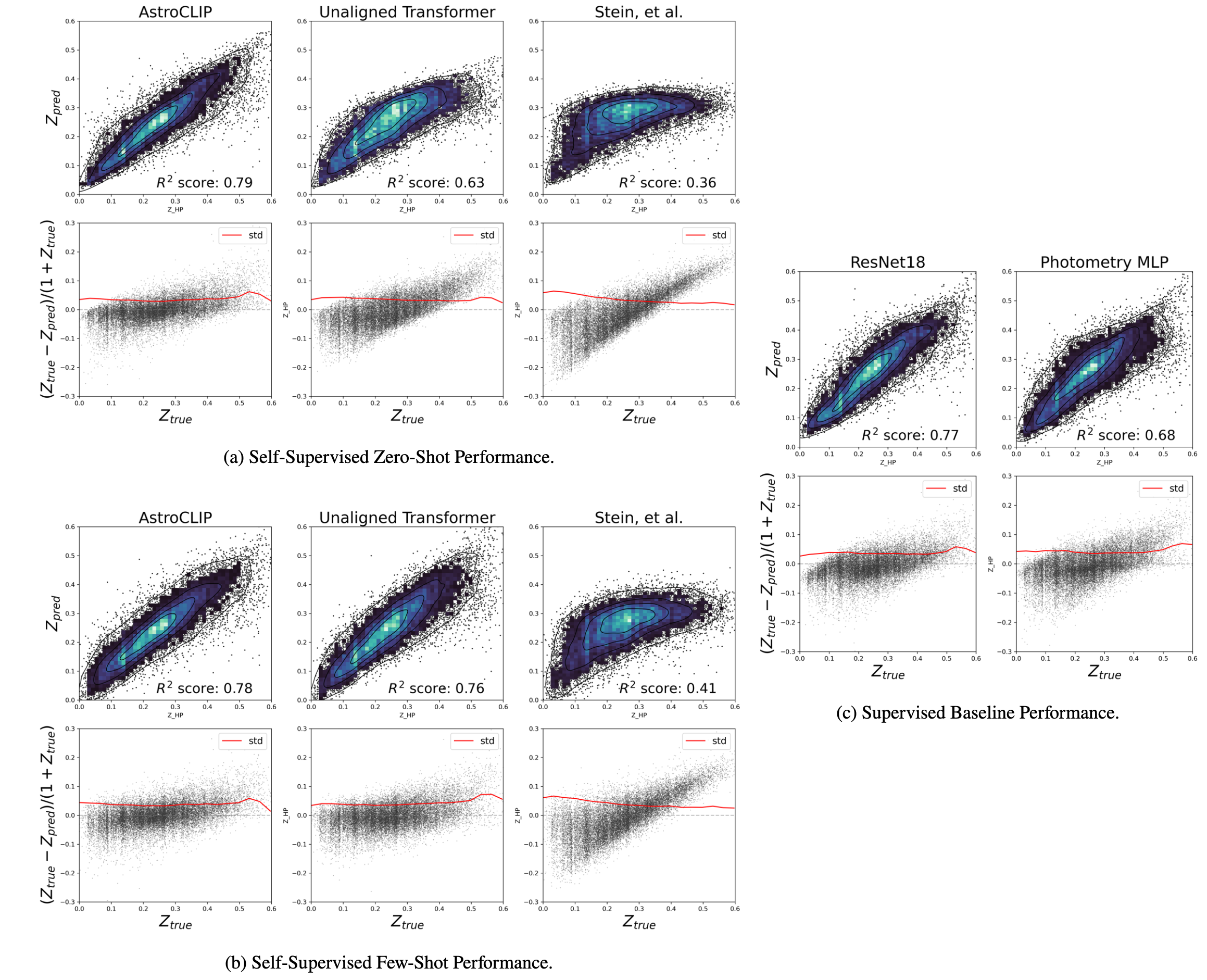
Redshift Estimation
We evaluate AstroCLIP’s performance on photometric redshift estimation, a common task in astrophysics that involves determining the distance of galaxies from their observed properties. Unlike traditional methods that require training dedicated convolutional neural networks from scratch, the galaxy embeddings generated from AstroCLIP are informative enough that even simple techniques like k-Nearest Neighbor and single-hidden-layer MLP regression can extract competitive redshift estimation results.
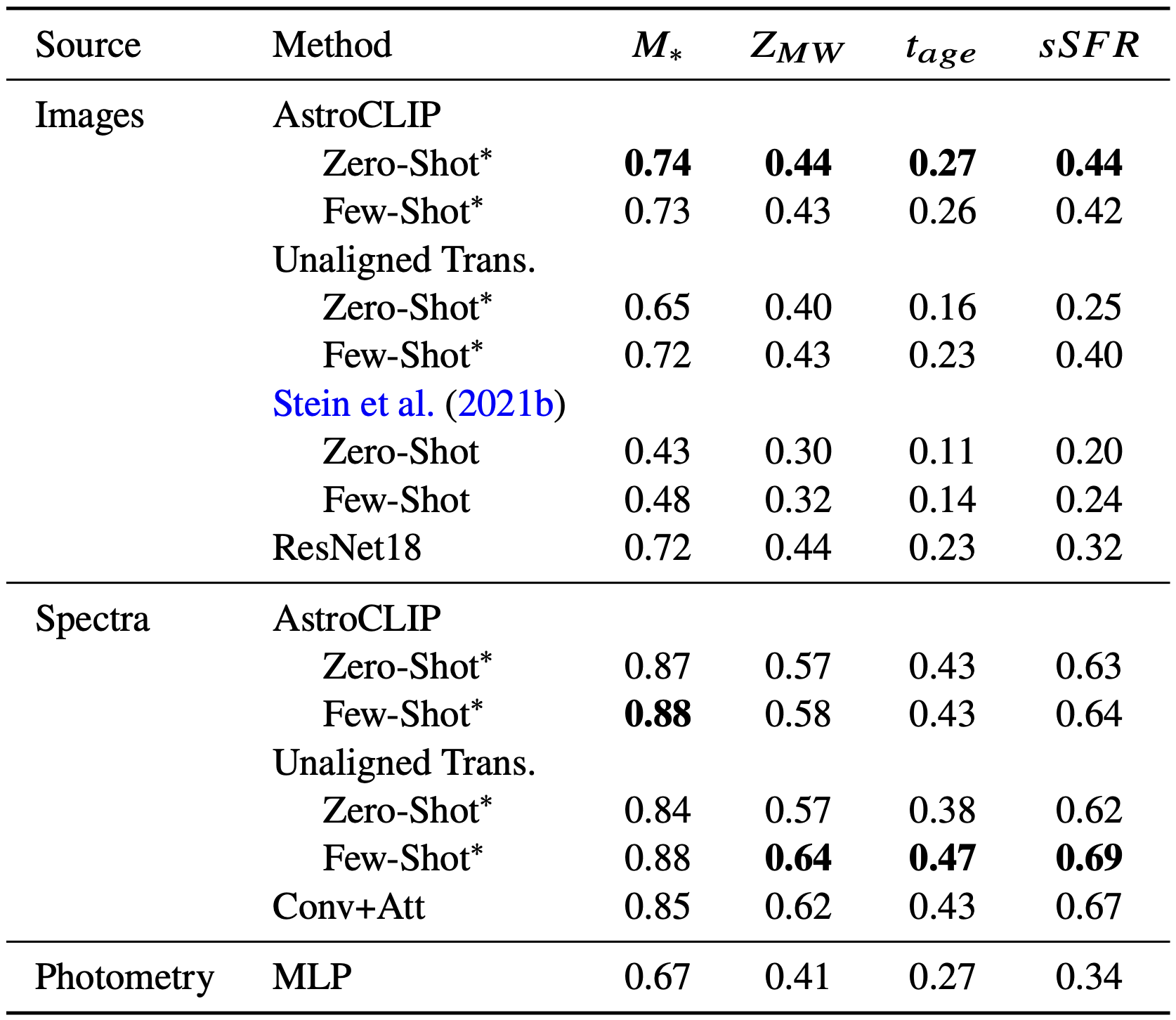
Physical Property Estimation
In addition to redshift, astronomers typically estimate additional galaxy properties, such as: Star Formation Rate: This measures the rate at which a galaxy forms new stars. High star formation rates indicate active, young galaxies, while lower rates suggest more mature or passive galaxies. Metallicity: Metallicity refers to the abundance of elements heavier than hydrogen and helium in a galaxy. It is a key indicator of the galaxy’s chemical evolution and past star formation history. Galaxy Age: This property estimates the time elapsed since the galaxy’s formation. It provides insight into the evolutionary stage of the galaxy, with older galaxies having undergone more dynamic processes and changes. Stellar Mass: Stellar mass is the total mass of all the stars within a galaxy. It is a fundamental property that influences the galaxy’s gravitational potential, dynamics, and overall structure. Overall, we show that AstroCLIP is once again able to effectively estimate important physical properties using basic regression tools (k-NN and MLP) from its embeddings, and outperforms its supervised counterparts despite no task-specific training.
Morphology Classification
Morphology classification is a fundamental task in understanding the formation and evolution of galaxies. By categorizing galaxies based on their shapes and structures, astronomers can gain insights into the dynamic processes that govern galaxy development. Once again, we demonstrate AstroCLIP’s ability to perform this task accurately despite no task-specific training.
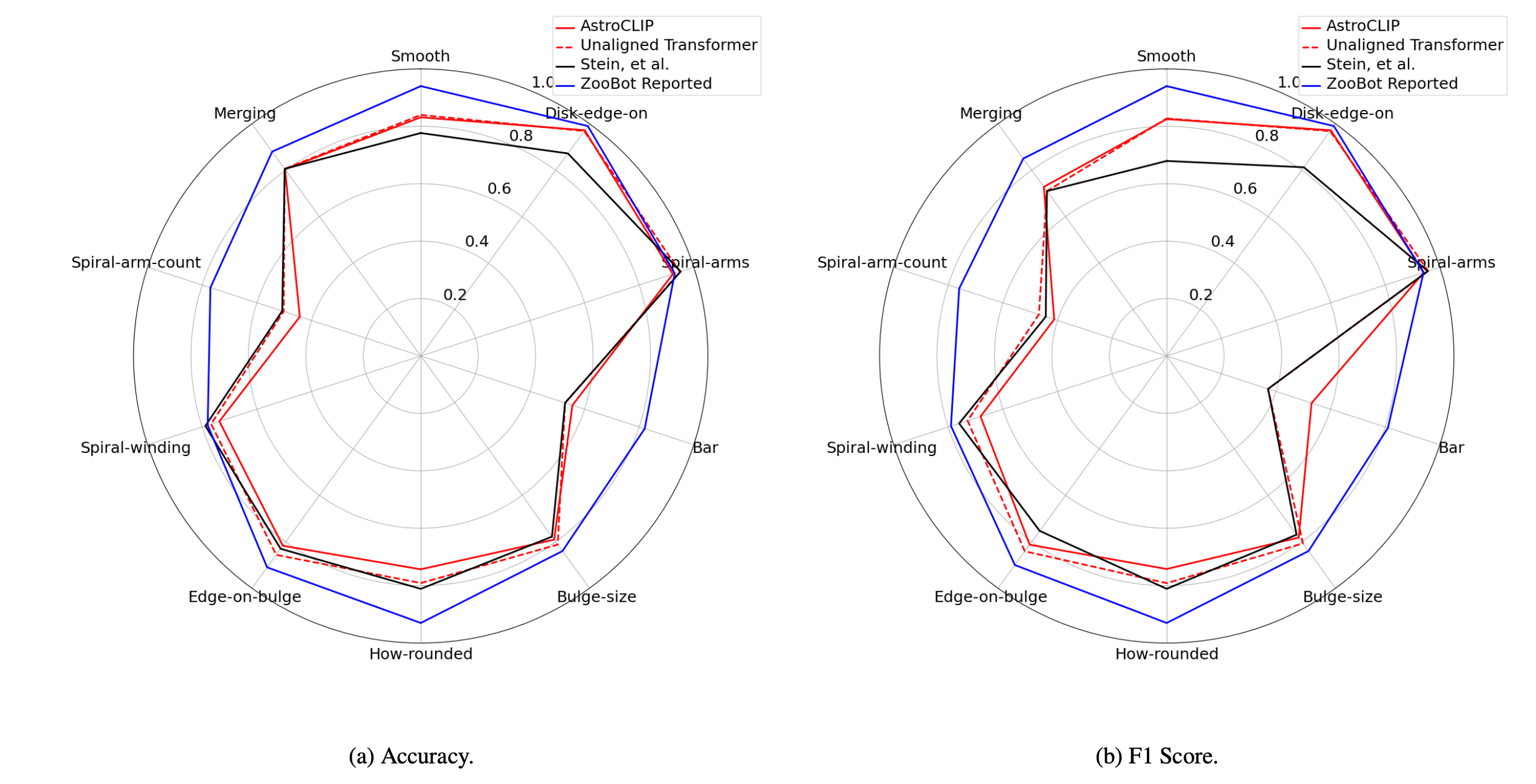
An Encouraging Observation
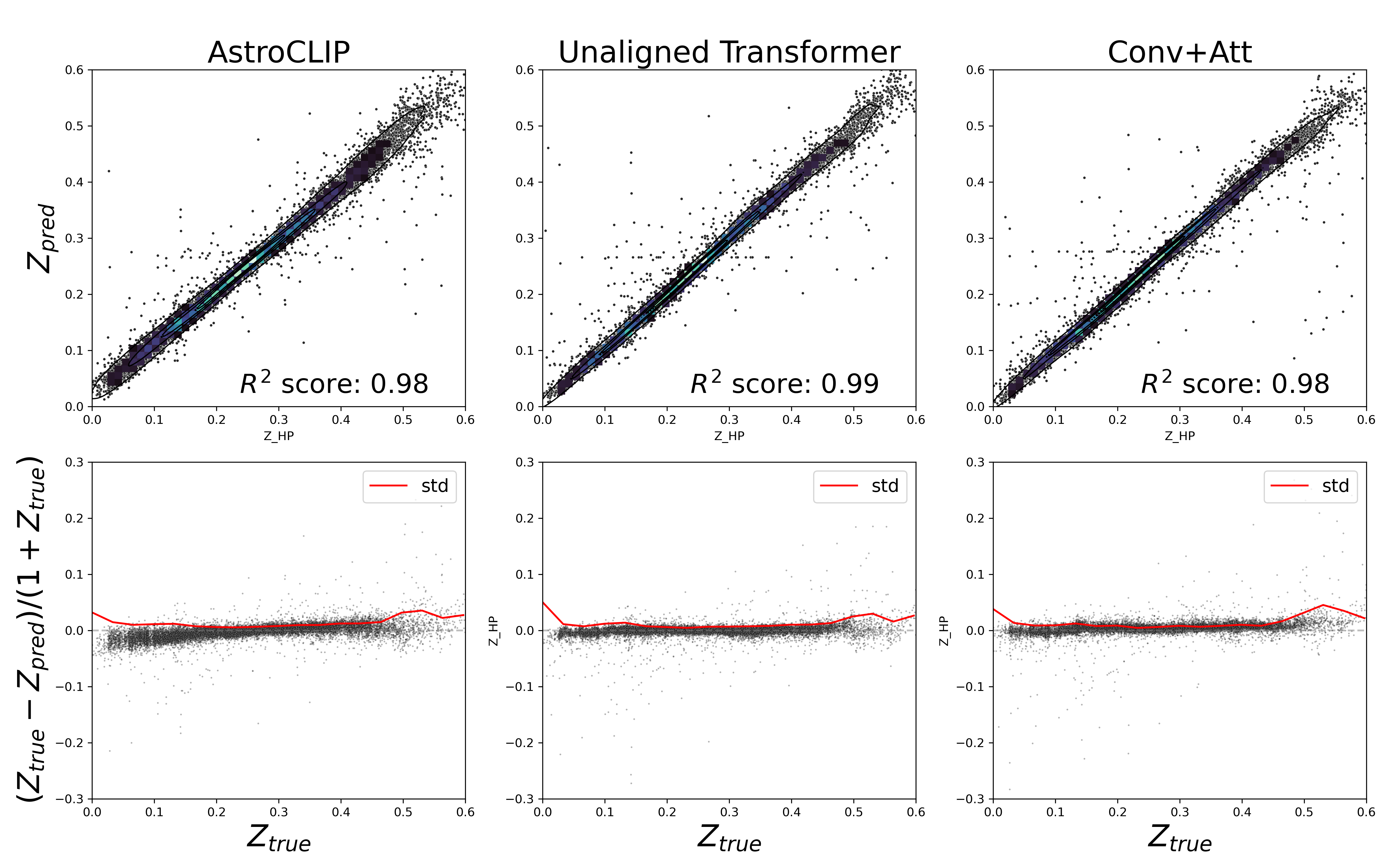
A galaxy’s spectrum typically provides perfect redshift information. However, because galaxy images do not perfectly convey redshift information, it was expected that AstroCLIP spectrum embeddings would lose some redshift data after CLIP alignment, as the training objective only promotes retaining the information that is shared between images and spectra. Surprisingly, this is not the case. Evaluating the AstroCLIP spectrum embeddings shows no significant loss of redshift information post-CLIP alignment. This finding suggests that cross-modal alignment, even with imperfectly informative modalities, can effectively retain information.
Similarly, we also find that alignment has not materially degraded AstroCLIP’s performance on morphology classification.
Conclusions
Our updated results demonstrate the potential of cross-modal contrastive pre-training to achieve high-quality foundation models for astronomical data, capable of performing downstream tasks even without fine-tuning. These include accurate in-modal and cross-modal semantic similarity search, photometric redshift estimation, galaxy property prediction from both images and spectra, and galaxy morphology classification. Ultimately, we contend that the model’s high performance on a wide variety of downstream tasks and its ability to retain modality-specific information are key properties to allow the community to build higher-level models that rely on off-the-shelf astronomical embeddings, just as CLIP language-image embeddings have enabled a wide variety of downstream applications in computer vision.